


1. はじめに
これまで、私はSnowflakeという名前こそ知っていたものの、その認識は「クラウド上の便利なデータベース」程度に過ぎませんでした。 もっと正直に言えば、Snowflakeがもたらす本質的な価値や、ほかのDWH(データウェアハウス)との差別性を十分に理解していませんでした。
そんな中、先日開催された初心者向けのセミナーに参加しました。 そこでようやく気付いたのは、Snowflakeが単なる「データを貯めるための箱」ではなく、 「貯めることと、分析することがセットのサイクルとして考えられている場所」だということです。
この気付きは、データ戦略を考える上で、かなり重要だと感じました。
本記事では、セミナーでの体験を通じ、あらためて「Snowflakeとは何なのか」を整理して解説します。
2. Snowflakeの基本理解
2.1 Snowflakeが解く問題
Snowflakeは、オンプレミスの基幹システムやSaaSなど、バラバラな場所にあるデータを一箇所に論理的に集約し、活用するためのハブのような存在です。
単にデータを保管するだけでなく、「DWH+分析」をストレスなく行うためにクラウド専用として生み出されています。 かつてのデータ活用で障壁となっていた「処理の重さ」や「データのコピー」といった問題を、独自のアーキテクチャで解決しています。
2.2 アーキテクチャの3層構造
Snowflakeの最大の特徴は、以下の3つの層が完全に独立して動いている点にあります。
- ストレージ層: データを一元的に保持し、物理コピーなしにスケーラビリティを実現します。
- 計算層(ウェアハウス): 計算リソースが完全に独立しているため、AIの重い処理を同時実行しても、隣で動いているBI(分析)ツールを重くすることがありません。
- クラウドサービス層: 認証やセキュリティ、ワークフロー管理を自動化し、インフラを意識せず「データの中身」に集中できる環境を提供します。
セミナーで聞いた「クエリが高速化しすぎて利用率が下がり、営業担当が困る(笑)」というエピソードは、この合理的な設計がもたらす圧倒的なパフォーマンスを象徴しています。
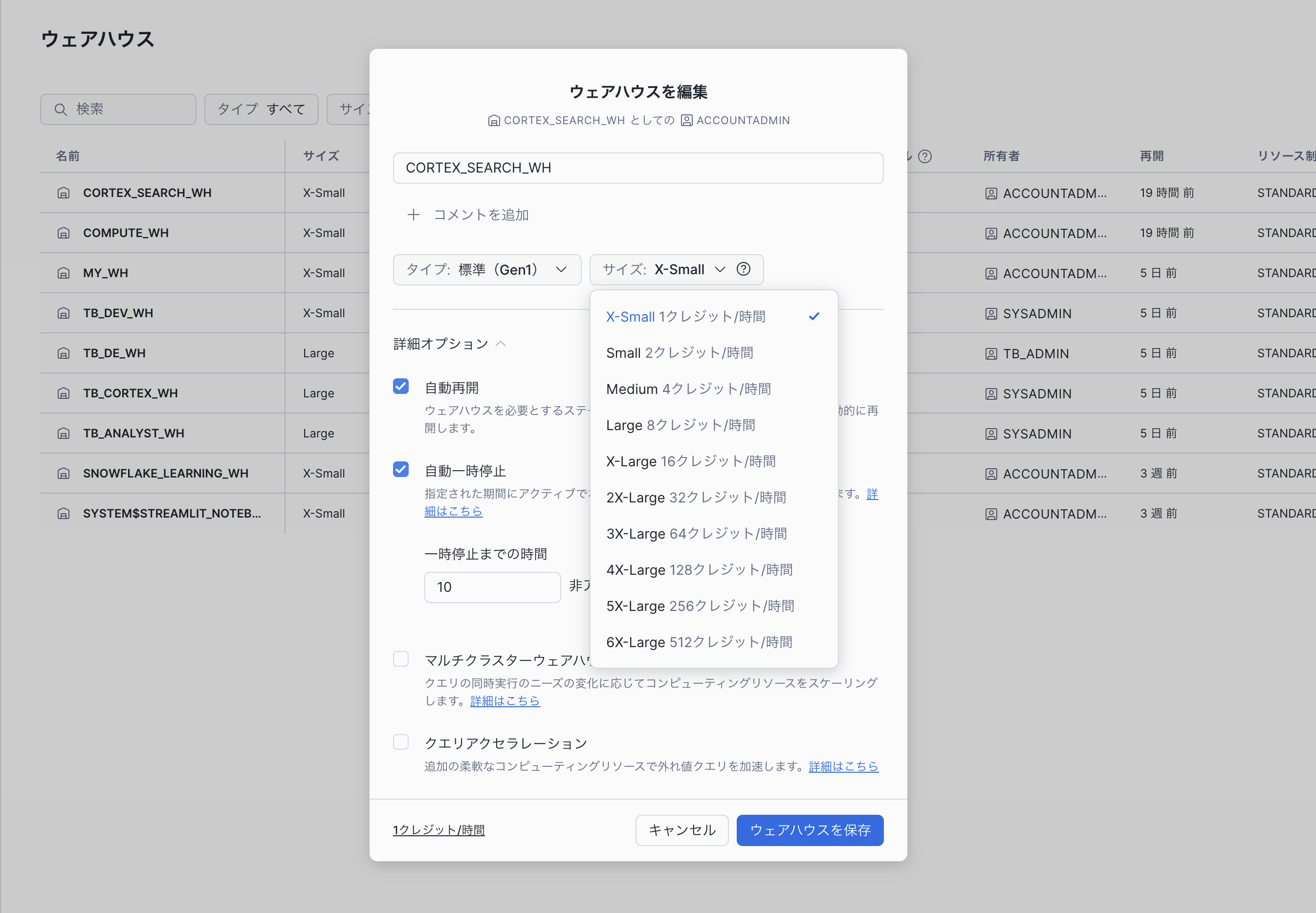
ちなみにですが、ウェアハウスのサイズ変更は、SQLコマンド1行で実行できます。
ALTER WAREHOUSE my_wh SET WAREHOUSE_SIZE = 'LARGE';
3. ハンズオンで体験した実務機能
セミナー後半のハンズオンでは、Snowflakeが「ただの箱」ではないことを証明する様々な活用法を体験しました。 ここでは、ワークショップで特に「開発効率」の観点から面白いと感じた機能を紹介します。
3.1 VARIANT型(JSONの直接操作)
JSONデータをパース(分解)せずにそのまま突っ込んで、SQLで直接中身を覗けます。
-- JSONの中身にドット記法や「:」で直接アクセス
SELECT
v:customer_id::int AS id,
v:order_details.item_name::string AS item
FROM raw_json_table;
3.2 ゼロコピークローン
物理コピーなしで、テスト環境を数秒で構築できます。
-- 本番テーブルを一瞬でクローン
CREATE OR REPLACE TABLE test_db.public.orders_clone
CLONE prod_db.public.orders;
4. ハンズオンで体験した「データの名寄せ」にAIを組み込む手法
セミナーのハンズオンで最も興味深かったのは、データの「name matching」(名寄せ)にAIを組み込む話です。
私が最も感動したポイントは、AIを「万能な判定機として使うのではなく、段階的に・目的に応じて活用する」という考え方でした。 これは実務的でもあり、コスト効率的でもあります。
4.1 実は、データの「ズレ」は想像以上に複雑
ハンズオンのシナリオ 複数の小売チェーン・EC企業から、日々の売上データがSnowflakeに投入されてきます。 しかし、各企業が独自のデータ形式で商品情報を管理しており、**表記ルールがバラバラ(いわば「データのサイロ化」)です。
- 小売チェーンA:「K社ビール/500ml」
- 小売チェーンB:「ビール缶(本体のみ)」
- EC企業:「K社/ビール」
一方、社内の商品マスターは「K社ビール 500ml」という統一規格です。
同じ商品なのに名前が違います。
直感的には「商品名が一致する行を JOIN すればいいのでは?」と思うかもしれません。 ですが、現実はそう甘くありません。
前処理を何もしない状態で、単純にテキスト比較してみると…
-- 何も加工処理せずに突合しようとしても…
SELECT COUNT(*)
FROM product_master AS m
INNER JOIN retail_data AS r
ON m.product_name = r.product_name;
-- 結果:ほぼ 0 件(マッチしない)
このズレを埋めるプロセスが「名寄せ」です。
4.2 実装のポイント:段階的なアプローチ
ハンズオンでは、この問題を3つのステップで段階的に解決していました。
ステップ1:従来的な手法で大多数を解決 → 高速・低コストで、データの大部分をマッチング
ステップ2:失敗ケースに対して、AIで精密な前処理を行い再マッチング → 改善失敗した分を救済
ステップ3:それでもマッチングできない少数派に対して、LLM(大規模言語モデル)が直接判定 → 最終確認・確定
では、詳しく見ていきましょう。
ステップ1:従来的な手法(正規表現 + ベクトル検索)
まずは「泥臭い」正規化から
- 正規表現で不要なタグ(
[期間限定]など)を削除 - 大文字・小文字・全角・半角を統一
- 余分な空白を除去
その後、テキストをベクトル化します。
embed_text_1024('multilingual-e5-large', product_name)
このベクトルは「テキストの意味」を数値で表現するもので、コンピューターが「似た意味のテキスト」を検索できるようになります。
コサイン類似度で商品を照合
vector_cosine_similarity(a.product_name_embed, b.product_name_embed) > 0.9
![]()
結果:大部分のマッチングに成功 ✅
…ですが、ここで壁にぶつかります。
正規化しても、商品マスターと小売・EC側のデータの「表現の多様性」が大きすぎるため、一定数のマッチングミスが発生してしまいました。
例えば…
- マスターの「K社ビール 500ml」に対して、小売データには「ビール缶(本体のみ)」のみ
- EC側には「K社/ビール」というようにスラッシュ区切り
- 同じ商品でも、記載方法がバラバラ こういったケースが、想像以上に多発しました。
ステップ2:AIで「データそのものを改善する」という発想
ここでAIの登場です。
ただし、AIに「この2つの商品は同じですか?」と直接判定させるのではなく、「データを整形・改善する」という役割を担わせるのです。
ステップ1で失敗したケースに対して、LLMにこう指示します:
「このテキストのメーカー名と商品名を分離してください」
AI_COMPLETE(
model => 'llama4-maverick',
prompt => '入力値からメーカーと商品名を分離してください。
メーカー名がない場合は空欄で返してください。
入力値は: ' || product_name
)
LLMは「K社」と「ビール 500ml」のようにメーカー名と商品名を自動で分離します。
ここが重要: AI_COMPLETE はデータ変換工具に過ぎない
「マッチング判定ではなく、データを整形している」という発想です。
その後、分離されたクリーンな「商品名だけ」を改めてベクトル化します。
embed_text_1024('multilingual-e5-large', sub_product_name)
メーカー名が含まれたままだと、ベクトル検索時にメーカー名の類似性に引っ張られてしまい、肝心の商品名の一致が疎かになることがあります。 LLMでこれらを分離し、分離されたクリーンな商品名に対応するベクトル情報を活用。既存のベクトル数値を用いて他の商品名との類似度を再計算することで、 純粋な「製品の類似性」を捉えられるようになります。
そして改めて、ベクトル検索を実施します。
vector_cosine_similarity(master_embed, cleaned_data_embed) > 0.9
結果:ステップ1で失敗したケースが改善 ✅
ステップ1で失敗したケースの多くが、このステップで救済されました。
ただし、ここにも「泥臭い工夫」が隠れている
AI_COMPLETEのプロンプトや temperature パラメータを細かく調整し、出力形式がJSONになるよう指示します。その後のベクトル化やマッチング閾値も最適化されます。
つまり、AIはあくまで「前処理のアシスタント」であり、最終的なマッチング精度は「ベクトル検索の効果」に依存するということです。
ステップ3:それでも残ったケースは、LLMに判定を依頼
ステップ2でも改善されないケースがまだ残ります。
ここで登場するのが「LLM as a Judge」という考え方です。
AI_COMPLETE(
model => 'claude-4-sonnet',
prompt => '以下の2つは同じ商品ですか?理由も含めてJSONで答えてください。
商品A: ' || product_name_master || '
商品B: ' || product_name ||
response_format => {
'type': 'json',
'schema': {
'properties': {
'score': {'type': 'number', 'description': '0〜1の一致度'},
'reason': {'type': 'string', 'description': '判定理由'}
}
}
}
)
人間が行う「最後の目視確認」をLLMに代行させる形です。
4.3 現実的な活用方針:コストと精度のバランス
この3段階のアプローチで気付いたのは、マッチング処理「パイプライン設計」を考えることが大切だということです。つまり、段階的なフィルタリングを通じて、必要な箇所に最適なツールを配置する戦略です。
-
ステップ1(正規表現+ベクトル検索):高速・低コスト
- 大量のデータを一度に処理でき、計算コストが低くて済みます
-
ステップ2(LLM前処理+再マッチング):中程度のコスト
- LLMは遅く、費用が掛かりますが、失敗したケースだけに適用
-
ステップ3(LLM判定+最終確認):最も費用が高い
- 「人間が判断するレベルの曖昧なケース」に対してのみ使用
つまり、「すべてのデータにAIを使うのではなく、必要な箇所に最適なツールを充てる」という発想が重要です。
余談:実は全件LLM判定に丸投げも可能
もちろん、ステップ1・2を飛ばして、すべてのマッチング判定をLLMに丸投げすることも技術的には可能です。 ですが、実務的には以下の理由から推奨されません:
- データ量が多い場合、処理時間が爆発的に増加:LLMは1件1件の判定に時間がかかるため、数万件のデータを処理するのは現実的ではありません
- コストが膨大になる:LLM APIの費用が累積し、ベクトル検索の数百倍の費用がかかることになります
- 精度は相対的に低下することもある:逆説的ですが、大量データを大量に処理するほど、応答のばらつきが増え、精度が低下することもあります
つまり、「精度を高めたければ段階的な処理が必要」であり、「処理速度と費用のバランスを取るには、適切なフィルタリング設計が必須」という教訓です。
実際のハンズオンでの実行結果は、以下の通りです:
| ステップ | 処理方法 | 対象データ | 新規マッチ件数 | コサイン類似度の成功 |
|---|---|---|---|---|
| ステップ1 | ベクトル検索 (正規化 + Cos類似度 > 0.9) |
全体 | 100件 | similarity ≥ 0.9 |
| ステップ2 | LLM前処理 (メーカー名・商品名の分離・正規化) |
Step 1で失敗した分 | 14件救済 | similarity_before < 0.9 → similarity_after ≥ 0.9 |
| ステップ3 | LLM最終判定 (Claude による確認) |
Step 2でも 改善されなかった分 |
14件確定 | LLM判定にて承認 |
各段階で「必要最小限のデータセット」にアプローチを変えることで、コスト効率を保ちながら段階的に精度を積み上げるというのが実務的なやり方です。
5. おわりに
初心者向けセミナーを経て理解したのは、Snowflakeは単なるDWHではなく、「データを価値に変えるための最短経路」であるということです。
このセミナーを通じて、特に印象に残ったのが以下の3点です:
- 泥臭い前処理はAIに任せられる(あるいはAIと協力できる)
- インフラの制約に悩むことなく、計算リソースを自由に拡張できる
- セキュアな環境でAIを交えた活用を進められる
「データがある場所でAIを動かす」というアプローチは、今後のデータ活用のスタンダードになると感じました。
「Snowflakeとは何か」を知ることは、「これからのデータ戦略をどう設計するか」を知ることに他なりません。
最後までお読みいただき、ありがとうございました。







