


はじめに
アジアクエスト デジタルエンジニアリング部AI/Dataエンジニアリング課の小林です。
昨今のDX推進、AI・IoT活用、データ分析等の爆発的な増加に伴い、データ基盤構築の需要が高まっています。
特に、大手の企業では自社が持つ膨大なデータを有効活用するため、データレイクハウスやデータウェアハウスを使用したデータの集約、分析が必要不可欠になってきています。
その中で「Databricks」というデータレイクハウスに触れることができましたので、特徴と基本的な使い方を紹介していきます。
データ基盤について
まず、Databricksの紹介をする前に、データ基盤に関する説明をします。
近年、多くの企業で「データ活用」が重要視されています。
売上や顧客行動、ログデータなど、業務のあらゆる場面で生成されたデータを分析・可視化することで意思決定の高度化や業務改善につなげる動きが加速しています。
その土台となるのが「データ基盤」です。
データ基盤とは、社内外に散在するデータを収集・蓄積・加工・分析できるように整備されたシステム群の総称です。
従来はオンプレミスのデータ基盤が主流でしたが、現在ではクラウドを前提とした構成が一般的になっています。
クラウド型データ基盤では、スケーラビリティや柔軟性が高く、大量データを効率的に扱える点が大きなメリットです。
一方で、ETL処理、分析基盤、機械学習環境などを個別に構築・連携する必要があり、設計や運用が複雑になりがちという課題もあります。
こうした背景から、「データ基盤を統合的に扱えるプラットフォーム」として注目されているのが「Databricks」です。
Databricksとは何か
Databricksは、Apache Sparkを中心技術として開発されたクラウドネイティブなデータ分析プラットフォームです。
Microsoft Azure、AWS、Google Cloudといった主要クラウド上で利用でき、データエンジニアリング、データ分析、機械学習を一つの環境で実行できます。
Databricks公式サイト
Databricksの大きな特徴は「Lakehouse(レイクハウス)」アーキテクチャです。
これは、データレイクの柔軟性とデータウェアハウスの信頼性・パフォーマンスを両立させる考え方で、 「Delta Lake」という仕組みによって実現されています。
「Delta Lake」により、トランザクション管理やスキーマ管理、履歴管理などが可能になり、 データレイクを業務で安心して利用できるようになります。
また、ノートブック形式の開発環境が提供されており、SQL、Python、Scala などを使って対話的に処理を記述できます。
これにより、データエンジニア、データサイエンティスト、分析担当者が同じ基盤上で協業しやすい点も Databricks の強みです。
Databricksで分析データを出力するまでの流れ
Databricksを使った基本的なデータ処理は、
データの状態を「ブロンズ」、「シルバー」、「ゴールド」の3層で管理する 「メダリオンアーキテクチャ」 という構成を採用することが一般的です。
必ずしもそのようにしなくとも良いですが、どのレベルのデータなのかがわかりやすくなります。
実際の流れは、以下のようになります。
1. データの取り込み(ブロンズ)
まず、クラウドストレージ(Azure Data Lake StorageやAmazon S3など)に格納されている生データをDatabricksに取り込みます。
形式はCSV、JSON、Parquetなどさまざまで、Apache Sparkの機能を使って高速に読み込むことができます。
また、ローカルに保存されているデータを取り込むことも可能です。
 このように、最初に取り込んだだけの状態のデータを「ブロンズ」と定義しています。
このように、最初に取り込んだだけの状態のデータを「ブロンズ」と定義しています。
2. データの加工(シルバー)
次に、読み込んだデータに対してクレンジングや変換処理を行います。
欠損値の補完、型変換、不要な列の削除、集計処理などを行い、分析やレポートに使いやすい形へ整形します。
この際、Delta Lake形式で保存することで、データの更新や再処理にも柔軟に対応できます。
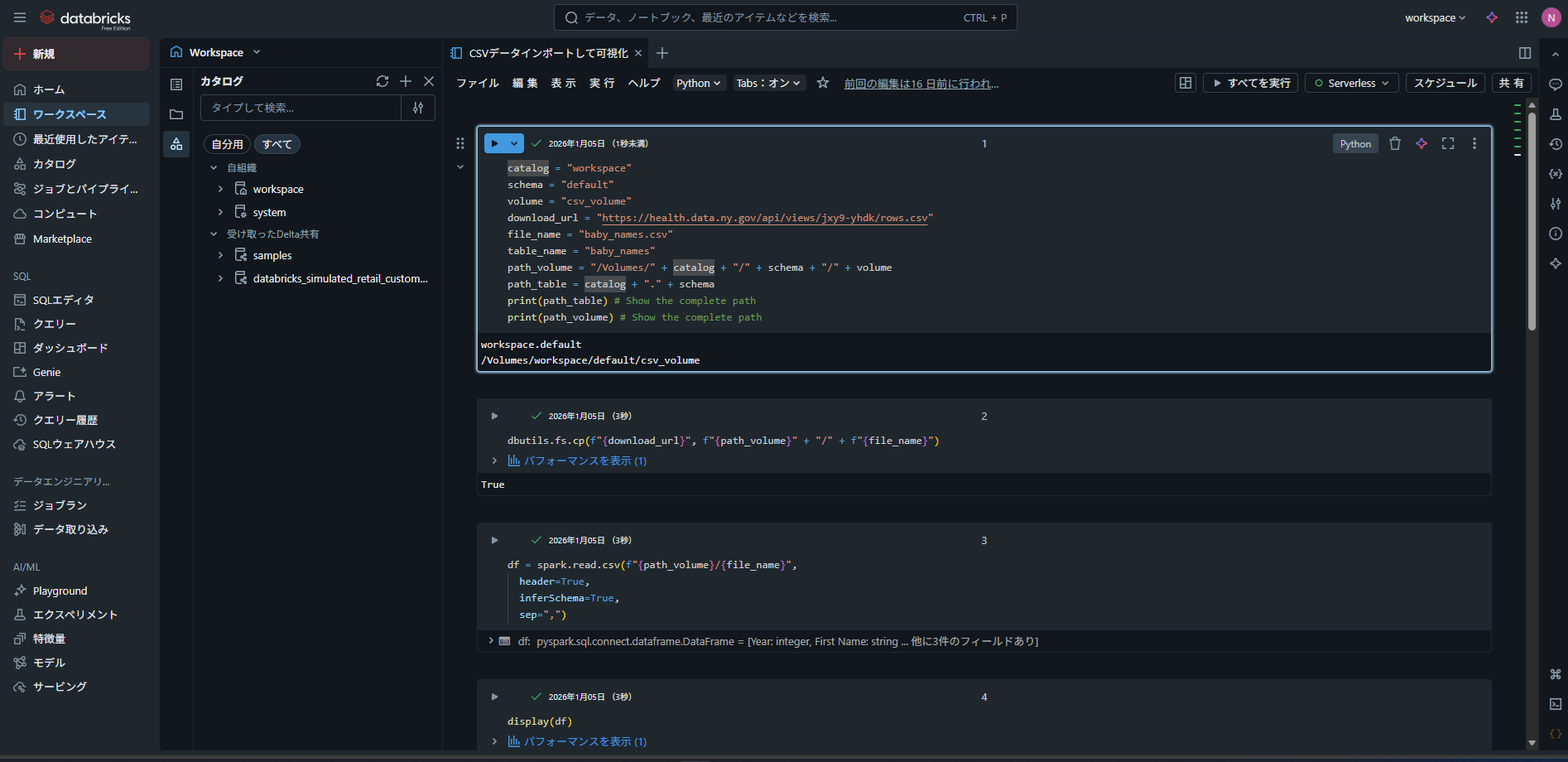
このように加工したデータの状態が「シルバー」となります。
3. データの活用・出力(ゴールド)
加工後のデータは、Databricks内でSQLによる分析を行ったり、BIツールと連携して可視化したりできます。
また、外部のデータベースや DWH へ書き出すことも可能です。
このように出力されたデータの状態が「ゴールド」となります。
これらはデータサイエンティストや企業の上層部が意思決定に使用します。
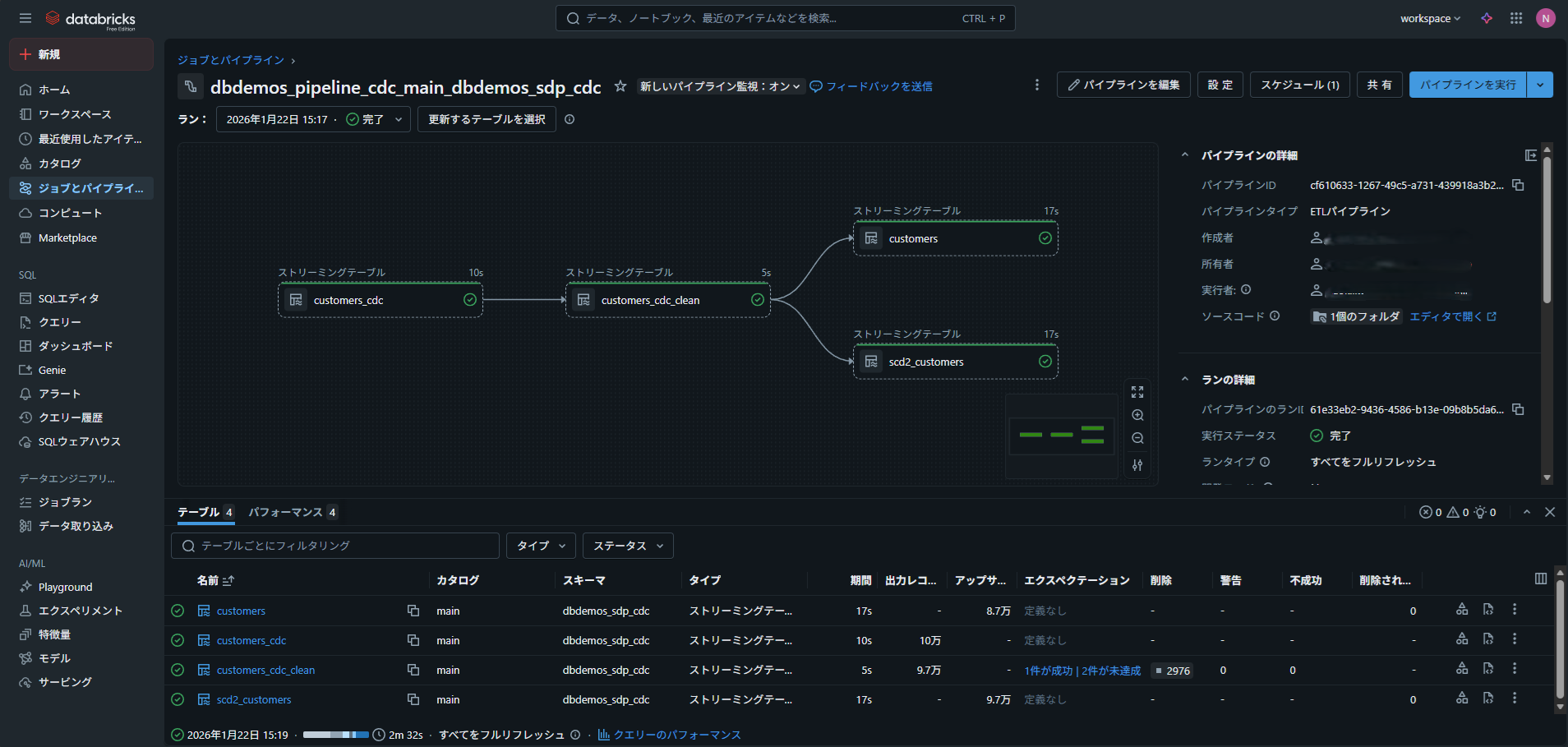
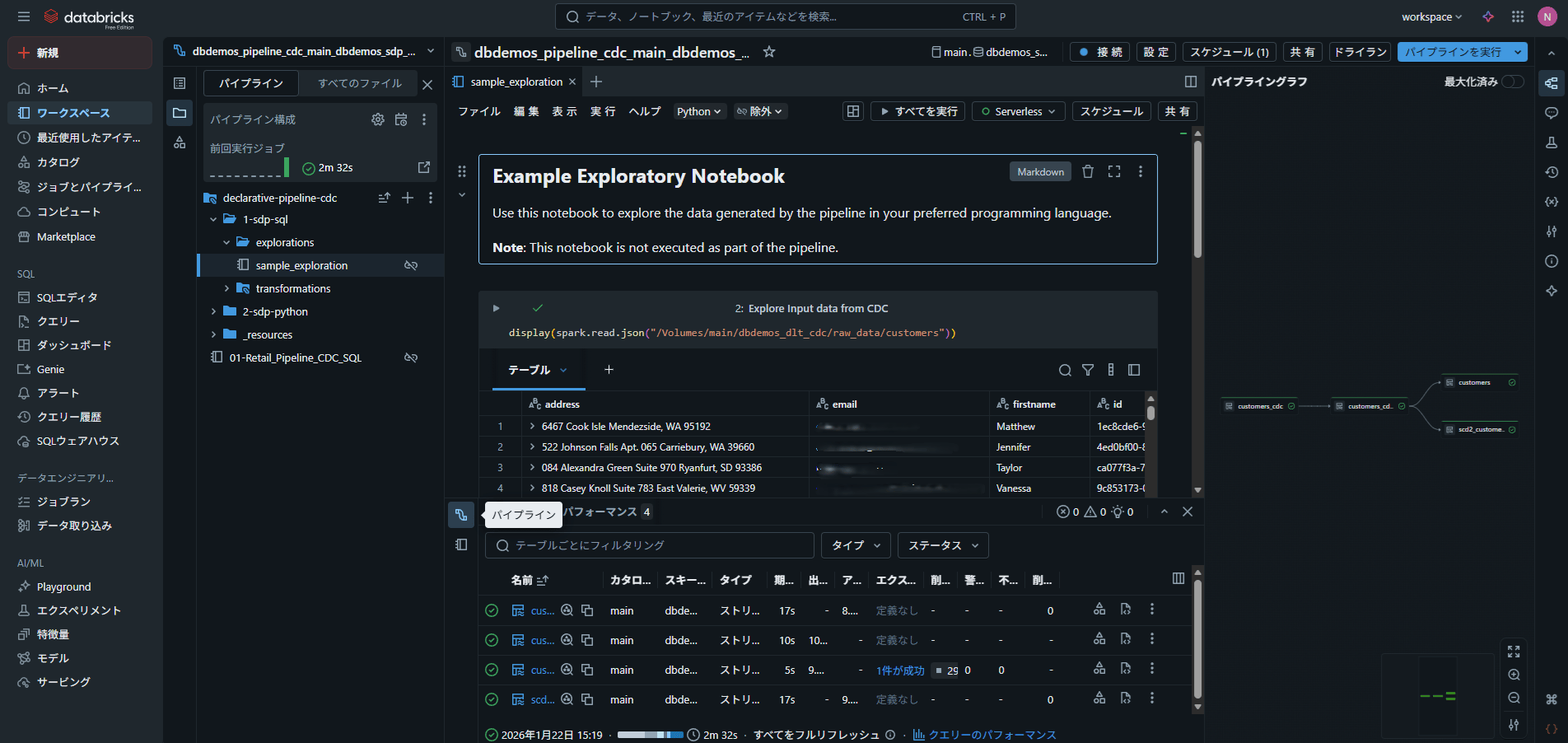
このように、Databricks は「取り込み → 加工 → 分析 → 出力」までを一貫して実行できる点が特徴です。
他のデータ基盤(Snowflake)との違い
Databricksとよく比較されるデータ基盤にSnowflakeがあります。
Snowflakeはクラウド型データウェアハウスとして高い人気を持ち、SQLベースでの分析に強みがあります。
両者の大きな違いは思想と得意分野です。
Snowflakeは構造化データを中心に、高速かつ安定した分析クエリを実行することに優れています。
一方、Databricksは構造化データだけでなく、半構造化・非構造化データや機械学習まで含めた幅広いデータ活用を想定しています。
また、DatabricksはSparkを活用した分散処理やプログラミングによる柔軟なデータ加工が可能で、データエンジニアリングや高度な分析に向いています。
SnowflakeはSQLによるシンプルな操作性が魅力で、BI用途や定型分析に強いと言えます。
どちらが優れているというよりも、「どのようなデータを、どのように活用したいか」によって選択が変わるツールだと言えるでしょう。
おわりに
かつては「ビッグデータ」という言葉で活用方法が話題になっていた時期もありました。
現在は、それらを活用することができる状況ができてきたのかなと思います。
今後、様々なシステムが生まれていき、そこから発生するデータはどんどん増えていきます。
それらを活用したいと考える企業も増えていくでしょうから、そこに対応できるデータ基盤構築の知識は、 新しいトレンドになっていくと思われます。
無料の非商用版であるDatabricks Free Editionであれば、
Googleアカウント等の連携でアカウント作成ができ、期間の制限なく学習用途で試すことが可能です。
Eラーニングやマニュアルの資料も充実しているので、気になる方は試していただければと思います。
まだまだチャンスが広がる分野だと思いますので、触れてみることをお勧めします。







