はじめに
業務でよく扱う帳票のひとつに「見積書」があります。 フォーマットが会社ごとにバラバラだったり、手書きに近い形式だったりと、ルールベースや正規表現だけで構造化するのはなかなか大変です。
今回はSnowflakeのCortex AI関数を使って、見積書PDFから明細情報を抽出し、テーブルに格納するまでを試してみました。
今回使うCortex AI関数
SnowflakeにはCortex AI関数と総称される関数群が用意されています。 今回使うのは以下の2つです。
AI_EXTRACT
ファイル(PDF・画像など)を入力として受け取り、指定したフォーマットで情報を抽出してくれる関数です。 質問形式でフィールドを定義するだけで、LLMがドキュメントの内容を読み取って答えてくれます。
https://docs.snowflake.com/ja/ja/user-guide/snowflake-cortex/document-extraction
AI_COMPLETE
モデルを指定してLLMを呼び出せる補完関数です。 任意のプロンプトを与えられるため、AI_EXTRACTでは対応しきれない細かい処理を補うのに使えます。
今回は、AI_COMPLETEの構造化出力機能を使っています。
https://docs.snowflake.com/ja/user-guide/snowflake-cortex/complete-structured-outputs
やること
このような見積書のPDFを用意します。
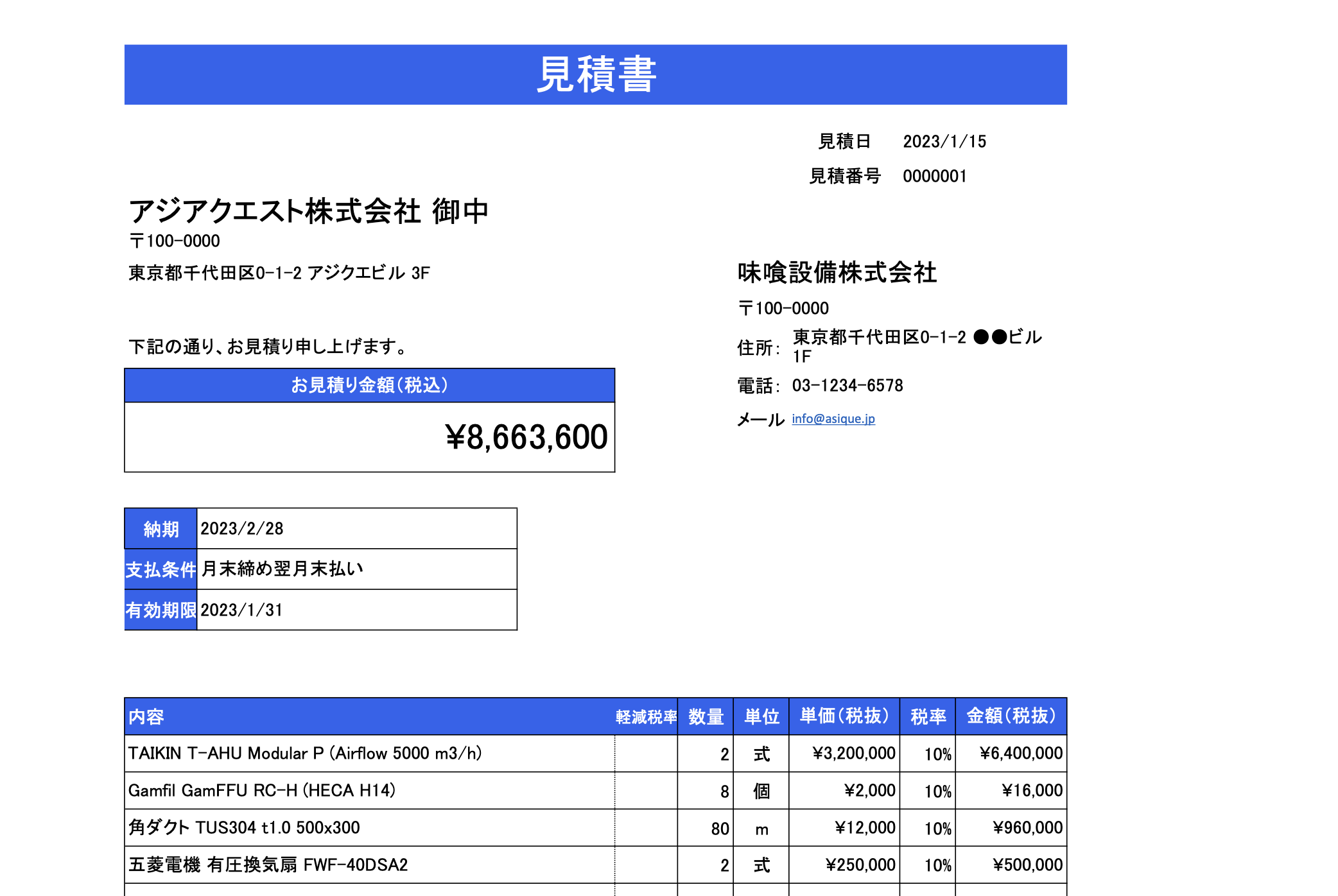
※本記事に掲載している見積書は説明用のサンプルであり、企業名・製品名・型番・金額等はすべて架空のものです。
この見積書から以下の情報を抽出して、Snowflakeのテーブルに格納します。
- 見積ヘッダー:会社名・見積番号・日付・合計金額・消費税額など
- 見積明細:製品名・数量・単価・金額など。さらにメーカー名・型番・仕様に分解する
テーブル定義
まず、抽出した情報を格納するテーブルを作成します。
-- 見積ヘッダー
CREATE OR REPLACE TABLE QUOTE_HEADERS (
QUOTE_ID STRING NOT NULL,
VENDOR_NAME STRING,
QUOTE_NO STRING,
QUOTE_DATE DATE,
CURRENCY STRING,
TOTAL_AMOUNT NUMBER(18,2),
TAX_AMOUNT NUMBER(18,2),
PAYMENT_TERMS STRING,
VALID_UNTIL DATE,
RAW_PAYLOAD VARIANT, -- 元JSON保持用
INGESTED_AT TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP(),
PRIMARY KEY (QUOTE_ID)
);
-- 見積明細
CREATE OR REPLACE TABLE QUOTE_LINE_ITEMS (
QUOTE_ID STRING NOT NULL,
LINE_NO NUMBER(10,0) NOT NULL,
-- 原文保持
RAW_NAME STRING, -- 例: TAIKIN T-AHU Modular P (Airflow 5000 m3/h)
RAW_SPEC STRING, -- 例: Airflow 5000 m3/h
-- 正規化項目(後段でAI_COMPLETEを使って埋める)
ITEM_TYPE STRING, -- ahu/ffu/duct/fan/...
MANUFACTURER STRING, -- TAIKIN/Gamfil/五菱電機 など
MODEL_NO STRING, -- T-AHU Modular P / GamFFU RC-H など
PRODUCT_NAME STRING, -- 製品名(型番を除いた名称)
QUANTITY NUMBER(18,3),
UNIT STRING,
UNIT_PRICE NUMBER(18,2),
LINE_AMOUNT NUMBER(18,2),
TAX_RATE NUMBER(5,2),
INGESTED_AT TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP(),
PRIMARY KEY (QUOTE_ID, LINE_NO),
FOREIGN KEY (QUOTE_ID) REFERENCES QUOTE_HEADERS(QUOTE_ID)
);
QUOTE_LINE_ITEMS の RAW_NAME には製品名・型番・仕様が混在したままの原文を保持しておき、後段の処理で分解します。
AI_EXTRACTでヘッダー情報を抽出する
まず見積書のヘッダー部分(全体の金額情報など)を抽出します。 AI_EXTRACT の responseFormat に質問と対応するフィールド名を渡すだけで、LLMがPDFを読んで答えてくれます。
-- 見積ヘッダーの取得
INSERT INTO TK.PUBLIC.QUOTE_HEADERS (
QUOTE_ID,
VENDOR_NAME,
QUOTE_NO,
QUOTE_DATE,
CURRENCY,
TOTAL_AMOUNT,
TAX_AMOUNT,
PAYMENT_TERMS,
VALID_UNTIL,
RAW_PAYLOAD
)
WITH extracted AS (
SELECT AI_EXTRACT(
file => TO_FILE('@TK.PUBLIC.FILES/sample1.pdf'),
responseFormat => [
['vendor_name', '発行元・会社名・販売者名は何ですか?'],
['quote_no', '見積番号・請求書番号は何ですか?'],
['quote_date', '見積日・請求日・発行日は何ですか?(YYYY-MM-DD形式で)'],
['currency', '通貨は何ですか?(JPY, USD等)'],
['total_amount', '合計金額・総額は何ですか?(数値のみ)'],
['tax_amount', '消費税額・税額は何ですか?(数値のみ)'],
['payment_terms', '支払条件・支払期限は何ですか?'],
['valid_until', '見積有効期限は何ですか?(YYYY-MM-DD形式で)']
]
) AS result
)
SELECT
UUID_STRING() AS QUOTE_ID,
result:response:vendor_name::STRING AS VENDOR_NAME,
result:response:quote_no::STRING AS QUOTE_NO,
COALESCE(
TRY_TO_DATE(result:response:quote_date::STRING, 'YYYY-MM-DD'),
TRY_TO_DATE(result:response:quote_date::STRING, 'YYYY/MM/DD'),
TRY_TO_DATE(result:response:quote_date::STRING, 'YYYY/M/D')
) AS QUOTE_DATE,
COALESCE(result:response:currency::STRING, 'JPY') AS CURRENCY,
TRY_TO_NUMBER(REGEXP_REPLACE(result:response:total_amount::STRING, '[^0-9.]', ''), 18, 2) AS TOTAL_AMOUNT,
TRY_TO_NUMBER(REGEXP_REPLACE(result:response:tax_amount::STRING, '[^0-9.]', ''), 18, 2) AS TAX_AMOUNT,
result:response:payment_terms::STRING AS PAYMENT_TERMS,
COALESCE(
TRY_TO_DATE(result:response:valid_until::STRING, 'YYYY-MM-DD'),
TRY_TO_DATE(result:response:valid_until::STRING, 'YYYY/MM/DD'),
TRY_TO_DATE(result:response:valid_until::STRING, 'YYYY/M/D')
) AS VALID_UNTIL,
result AS RAW_PAYLOAD
FROM extracted;
日付のフォーマットが揺れる可能性があるため、COALESCE + TRY_TO_DATE で複数パターンに対応しています。 金額も ¥ や , が混ざることがあるので REGEXP_REPLACE で数値以外を除いてから変換しています。
見積ヘッダーの抽出結果

問題なさそうです。
AI_EXTRACTで明細行を抽出する
明細行とはこの部分です。
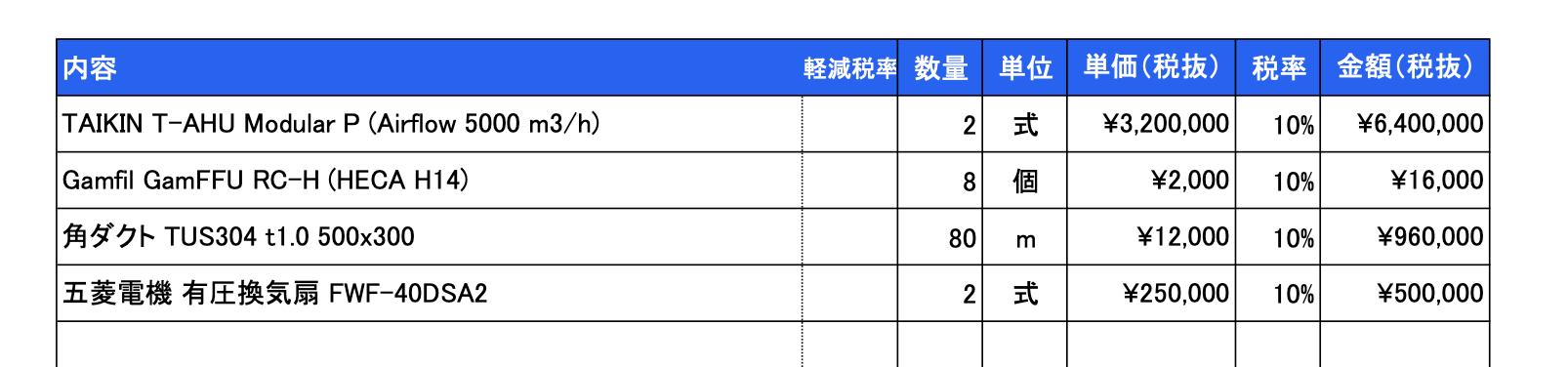
続けて、明細の各行をJSON配列として抽出します。 LATERAL FLATTEN を使ってJSON配列を展開し、1行ずつレコードに変換します。
-- 明細行の抽出・挿入
INSERT INTO TK.PUBLIC.QUOTE_LINE_ITEMS (
QUOTE_ID, LINE_NO, RAW_NAME, ITEM_TYPE, RAW_SPEC, QUANTITY, UNIT, UNIT_PRICE, LINE_AMOUNT, TAX_RATE
)
WITH extracted AS (
SELECT AI_EXTRACT(
file => TO_FILE('@TK.PUBLIC.FILES/sample1.pdf'),
responseFormat => [
['line_items', 'すべての明細行をJSON配列で抽出。各要素は必ず {"name":"製品名", "item_type":"種類", "spec":"仕様", "quantity":数量, "unit":"単位", "unit_price":単価, "line_amount":金額, "tax_rate":税率} の形式のJSONオブジェクトにすること']
]
) AS result
),
header AS (
SELECT QUOTE_ID FROM TK.PUBLIC.QUOTE_HEADERS WHERE QUOTE_NO = '0000001' ORDER BY INGESTED_AT DESC LIMIT 1
),
parsed AS (
SELECT PARSE_JSON(f.VALUE::STRING) AS item
FROM extracted e, LATERAL FLATTEN(input => e.result:response:line_items) f
)
SELECT
h.QUOTE_ID,
ROW_NUMBER() OVER (ORDER BY 1),
p.item:name::STRING,
p.item:item_type::STRING,
p.item:spec::STRING,
TRY_TO_NUMBER(REGEXP_REPLACE(p.item:quantity::STRING, '[^0-9.]', ''), 18, 3),
p.item:unit::STRING,
TRY_TO_NUMBER(REGEXP_REPLACE(p.item:unit_price::STRING, '[^0-9.]', ''), 18, 2),
TRY_TO_NUMBER(REGEXP_REPLACE(p.item:line_amount::STRING, '[^0-9.]', ''), 18, 2),
TRY_TO_NUMBER(REGEXP_REPLACE(p.item:tax_rate::STRING, '[^0-9.]', ''), 5, 2)
FROM parsed p CROSS JOIN header h;
AI_COMPLETEでさらに細かく分解する
さて、ここからは実践的かつ泥臭い内容となります。
明細の RAW_NAME(製品名欄)には「メーカー名」「型番」「仕様」が1つの文字列に混在していることがあります。 例えば TAIKIN T-AHU Modular P (Airflow 5000 m3/h) のような形式です。
AI_EXTRACTではLLMモデルを指定できないため、この分解処理の精度が上がりきりませんでした。 そこで、AI_COMPLETEを使い、モデルを指定してより精度の高い抽出を行います。
MERGE INTO TK.PUBLIC.QUOTE_LINE_ITEMS t
USING (
SELECT
q.QUOTE_ID,
q.LINE_NO,
ex.result:manufacturer::STRING AS new_manufacturer,
ex.result:model_no::STRING AS new_model_no,
ex.result:product_name::STRING AS new_product_name,
ex.result:item_type::STRING AS new_item_type,
ex.result:raw_spec::STRING AS new_raw_spec
FROM TK.PUBLIC.QUOTE_LINE_ITEMS q,
LATERAL (
SELECT AI_COMPLETE(
model => 'claude-3-5-sonnet',
prompt => '空調設備見積の製品名から情報を抽出せよ。
入力: ' || q.RAW_NAME || '
抽出ルール:
- manufacturer: メーカー名。なければnull
- model_no: 型番・材質コード。なければnull
- product_name: 製品種別(AHU/FFU/角ダクト/有圧換気扇等)
- item_type: ffu/ahu/duct/fanの4択
- raw_spec: 寸法・板厚・流量等の数値仕様。なければnull
- 値が不明・該当なしの場合は必ずnullを出力(UNKNOWN等のプレースホルダは不可)',
response_format => TYPE OBJECT(
manufacturer STRING,
model_no STRING,
product_name STRING,
item_type STRING,
raw_spec STRING
),
model_parameters => {'temperature': 0}
) AS result
) ex
WHERE q.QUOTE_ID IN (SELECT QUOTE_ID FROM TK.PUBLIC.QUOTE_HEADERS WHERE QUOTE_NO = '0000001')
) s
ON t.QUOTE_ID = s.QUOTE_ID AND t.LINE_NO = s.LINE_NO
WHEN MATCHED THEN UPDATE SET
t.MANUFACTURER = s.new_manufacturer,
t.MODEL_NO = s.new_model_no,
t.PRODUCT_NAME = s.new_product_name,
t.ITEM_TYPE = s.new_item_type,
t.RAW_SPEC = s.new_raw_spec;
モデルに claude-3-5-sonnet を指定することで、メーカー名の判別精度がAI_EXTRACTより大幅に向上しました。

しかし、結果を見ると細かい問題があります。 型番や仕様、製品名がうまく分離できていません。
例えば「角ダクト TUS304 t1.0 500x300」の場合、仕様に「t1.0 500x300」が、製品名に「TUS304」が入って欲しいです。
これは、モデルをclaude-4-6-sonnetなどに変えてみたりしても改善しませんでした。 さらに上位のopusなどに変えるとうまくいく可能性もありましたが、費用もその分高くなるので別のアプローチを考えました。
自己診断フェーズを追加する
上記の問題を1つのAI_COMPLETEで解決するのではなく、結果を自己診断させるフェーズを追加してみました。
-- 自己診断・修正
MERGE INTO TK.PUBLIC.QUOTE_LINE_ITEMS t
USING (
SELECT
q.QUOTE_ID,
q.LINE_NO,
ex.result:manufacturer::STRING AS new_manufacturer,
ex.result:model_no::STRING AS new_model_no,
ex.result:product_name::STRING AS new_product_name,
ex.result:item_type::STRING AS new_item_type,
ex.result:raw_spec::STRING AS new_raw_spec
FROM TK.PUBLIC.QUOTE_LINE_ITEMS q,
LATERAL (
SELECT AI_COMPLETE(
model => 'claude-3-5-sonnet',
prompt => 'RAW_NAMEから抽出した結果を検証し、漏れがあれば修正せよ。
RAW_NAME: ' || q.RAW_NAME || '
現在の抽出結果:
- manufacturer: ' || COALESCE(q.MANUFACTURER, 'null') || '
- model_no: ' || COALESCE(q.MODEL_NO, 'null') || '
- product_name: ' || COALESCE(q.PRODUCT_NAME, 'null') || '
- item_type: ' || COALESCE(q.ITEM_TYPE, 'null') || '
- raw_spec: ' || COALESCE(q.RAW_SPEC, 'null') || '
修正ルール:
- RAW_NAMEの要素で未割当のものがあれば適切なフィールドに追加
- product_nameは製品種別のみ(AHU/FFU/角ダクト/有圧換気扇等)。型番や仕様は含めない
- raw_specは数値を含む寸法・流量のみ。該当なければnull
- 値が不明・該当なしの場合は必ずnullを出力(UNKNOWN等のプレースホルダは不可)
- 既に正しく抽出されている値は変更しない',
response_format => TYPE OBJECT(
manufacturer STRING,
model_no STRING,
product_name STRING,
item_type STRING,
raw_spec STRING
),
model_parameters => {'temperature': 0}
) AS result
) ex
WHERE q.QUOTE_ID IN (SELECT QUOTE_ID FROM TK.PUBLIC.QUOTE_HEADERS WHERE QUOTE_NO = '0000001')
) s
ON t.QUOTE_ID = s.QUOTE_ID AND t.LINE_NO = s.LINE_NO
WHEN MATCHED THEN UPDATE SET
t.MANUFACTURER = s.new_manufacturer,
t.MODEL_NO = s.new_model_no,
t.PRODUCT_NAME = s.new_product_name,
t.ITEM_TYPE = s.new_item_type,
t.RAW_SPEC = s.new_raw_spec;

結果、これがうまく機能し、メーカー名・型番・仕様がきれいに分離されてテーブルに格納されています。
金額の整合性の確認
見積書全体の金額と明細の金額を集計して、整合性をチェックしてみます。
-- QUOTE_LINE_ITEMSとQUOTE_HEADERSの価格整合性チェック
-- ※ヘッダーのTOTAL_AMOUNTは税込、明細のLINE_AMOUNTは税抜を前提
SELECT
h.QUOTE_ID,
h.QUOTE_NO,
h.TOTAL_AMOUNT AS header_total_incl_tax,
h.TAX_AMOUNT AS header_tax,
SUM(l.LINE_AMOUNT) AS line_items_subtotal,
SUM(l.LINE_AMOUNT * COALESCE(l.TAX_RATE, 0) / 100) AS line_items_tax,
SUM(l.LINE_AMOUNT) + SUM(l.LINE_AMOUNT * COALESCE(l.TAX_RATE, 0) / 100) AS line_items_total_incl_tax,
h.TOTAL_AMOUNT - (SUM(l.LINE_AMOUNT) + SUM(l.LINE_AMOUNT * COALESCE(l.TAX_RATE, 0) / 100)) AS total_diff,
h.TAX_AMOUNT - SUM(l.LINE_AMOUNT * COALESCE(l.TAX_RATE, 0) / 100) AS tax_diff,
CASE
WHEN ABS(h.TOTAL_AMOUNT - (SUM(l.LINE_AMOUNT) + SUM(l.LINE_AMOUNT * COALESCE(l.TAX_RATE, 0) / 100))) <= 0.01
AND ABS(h.TAX_AMOUNT - SUM(l.LINE_AMOUNT * COALESCE(l.TAX_RATE, 0) / 100)) <= 0.01
THEN '✓ 一致'
ELSE '✗ 不一致'
END AS status
FROM TK.PUBLIC.QUOTE_HEADERS h
LEFT JOIN TK.PUBLIC.QUOTE_LINE_ITEMS l ON h.QUOTE_ID = l.QUOTE_ID
GROUP BY h.QUOTE_ID, h.QUOTE_NO, h.TOTAL_AMOUNT, h.TAX_AMOUNT
ORDER BY status DESC, h.QUOTE_NO;

一致していました。不整合の場合は再試行したり、フラグを付けておいたりする運用も考えられます。
さいごに
SnowflakeのCortex AI関数(AI_EXTRACT / AI_COMPLETE)を使うことで、従来のルールベースや正規表現では対応が難しかった非定型な見積書PDFからの情報抽出が実現できました。
特にAI_EXTRACTはファイルを渡して質問するだけで構造化できるため、導入コストが低い点が魅力です。 さらに精度を求める箇所は、AI_COMPLETEでモデルを指定して補う、という組み合わせが有効だと感じました。
SnowflakeのAI機能はまだ進化の途中なので、今後のアップデートにも注目していきたいところです。
当社ではSnowflakeに関する導入支援を行っておりますので、ご興味のある方はぜひお問い合わせください。