


この記事で学べること
.docx/.xlsxがGitの差分管理を根本的に破壊する技術的な理由- LLMにWordファイルを渡すとコストと精度に何が起きるか
- Apache POIの命名の裏側にみる「Officeフォーマットの本質的な限界」
- Docs as CodeとMarkdown移行で開発ドキュメントをCI/CDに組み込む具体的な方法
はじめに
「要件定義書_最終版_v2.docx」──そんなファイル名を見たことがある方、多いのではないでしょうか。私はあります。何度も。
私のチームでも、仕様書やテスト設計書をWordやExcelで管理しているプロジェクトが今もあります。しかしGitとCIが当たり前になり、さらにClaude・GPT・GeminiといったLLMを開発フローに使い始めたころから「このフォーマット、根本的にまずいな」と感じるようになりました。
本記事では、その「まずさ」を技術的に掘り下げながら、Markdownへの移行がなぜ戦略的な正解なのかを解説します。Officeファイルに疲弊している方にぜひ読んでほしい内容です。
背景・課題
チームメンバーが同じ仕様書を同時に編集してコンフリクトが起きたとき、私たちにできることは「どちらかを上書き」するしかありませんでした。GitのDiffには「バイナリファイルが変わった」としか出ない。Pull Requestでインラインレビューもできない。そしてLLMに仕様を読み込ませたら、意図した内容よりXMLのタグのほうが多くて精度が出ない──。
こうした問題は、Officeフォーマットが「人間の視覚的なレイアウト再現のために設計されたアーキテクチャ」であるという本質的な限界から来ています。
GitアーキテクチャからOOXMLの限界を読み解く
.docxや.xlsxの実態は、OOXML(Office Open XML:MicrosoftがISO/IEC 29500として標準化したオフィス文書フォーマット規格)に従い、膨大なXMLファイルとメディアリソースをZIP圧縮したアーカイブ(複数のファイルをひとまとめにした圧縮パッケージ)です。Gitはこれをバイナリ(テキストではなく0と1のビット列として記録された、人間が直接読めない形式のファイル)の塊(Blobオブジェクト)として扱うため、行単位の差分(Diff)が取れません。
変数名1つを修正しても、ZIP圧縮のハッシュ値が変わり、「ファイル全体が置換された」という記録しか残りません。これが意味することは:
- 過去の仕様変更が追跡できない(
git blame・git bisectが使えない) - 並行編集でコンフリクト解決が不可能(一方の変更を丸ごと捨てるしかない)
- リポジトリが加速度的に肥大化する(Gitのデルタ圧縮がバイナリに対しては効かないため)
対して、Markdownはプレーンテキストなので、Gitが行単位・単語単位で差分を追跡できます。GitHub上ではネイティブレンダリングされ、Pull Requestでコードと同じUIを使ったインラインレビューも可能です。
| 評価項目 | Markdown (.md) | OOXML (.docx/.xlsx) |
|---|---|---|
| GitのDiff | 行・単語単位で表示可 | バイナリ置換として扱われる |
| 自動マージ | 行単位でマージ可能 | 不可。上書きのみ |
| GitHubプレビュー | ネイティブサポート | ダウンロードして目視での確認が必要 |
| PRインラインレビュー | 行単位コメント可 | 不可能 |
| リポジトリ容量 | デルタ圧縮が有効 | 更新ごとに全体保存で肥大化 |
LLMにOfficeファイルを渡すべきでない理由
Claude・ChatGPT・GitHub Copilotなどを使うとき、仕様書をコンテキストとして渡すことが増えています。このとき、ファイルフォーマットがAIの精度とコストに直接影響します。
LLMは入力を「トークン」という単位で処理します。Markdownなら# 見出しや- 箇条書きの記号は数トークン以下です。しかし.docxの内部XMLを展開してLLMに渡すと、次のような構造が大量に流れ込みます。
<w:p>
<w:pPr>
<w:jc w:val="left"/>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="MS Mincho" w:hAnsi="MS Mincho" w:eastAsia="MS Mincho"/>
<w:sz w:val="24"/>
</w:rPr>
<w:t>こんにちは</w:t>
</w:r>
</w:p>
「こんにちは」の5文字を伝えるために、フォント名・サイズ・レイアウト情報を持つXMLタグが大量のトークンを消費しています。意味のある情報(Signal)ではなくメタデータ(Noise)でコンテキストウィンドウが埋まるため、次の問題が発生します。
- APIコストが不必要に増大する(同じ内容でもトークン数が数倍になる)
- LLMの注意力がメタデータに分散される(仕様というコア情報がノイズに埋もれてハルシネーションが起きやすくなる)
Markdownに変換するだけで、同じコンテキストウィンドウに何倍もの意味ある情報を詰め込めます。これはプロンプトエンジニアリングの観点からも、最も合理的なデータクレンジング手法です。
実際に計測してみた
「推測するな、計測せよ」という言葉の通り、同じ内容の開発ドキュメント(ユーザー認証設計書)を3つのフォーマットで用意し、tiktoken(GPT-4 / cl100k_base) でトークン数を実測しました。
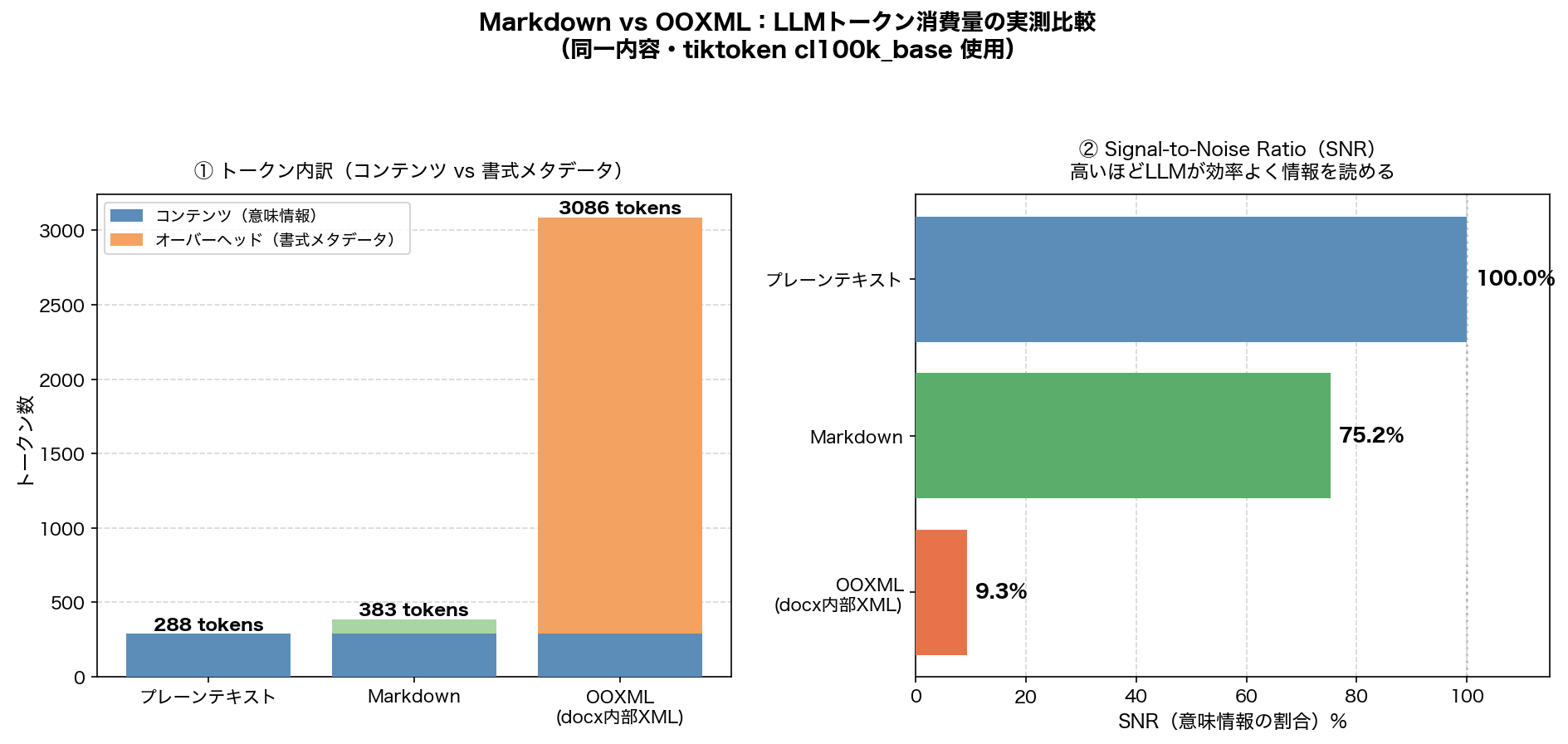
| フォーマット | トークン数 | プレーンテキスト比 | SNR(意味情報の割合) |
|---|---|---|---|
| プレーンテキスト | 288 | 1.0x | 100.0% |
| Markdown | 383 | 1.3x | 75.2% |
| OOXML(docx内部XML) | 3,086 | 10.7x | 9.3% |
結果は想定を上回るものでした。OOXMLはMarkdownの約8倍、プレーンテキストの約11倍のトークンを消費します。SNR(意味情報の割合)はわずか9.3%、つまりLLMに渡したトークンの9割以上が「フォントの種類」や「余白の設定」といった、AIにとって無価値な書式情報ということになります。
Markdownはマークアップのオーバーヘッドが1.3倍に抑えられており、SNRも75%以上を保っています。同じAPIコストで、OOXMLの8倍近い量の仕様情報をLLMに読ませられる計算です。
Apache POIが語るOfficeフォーマットの本質
「Officeフォーマットはプログラムによる処理に向いていない」──この事実を、ある歴史的エピソードが雄弁に語っています。
JavaでMicrosoft Officeファイルを扱うデファクトライブラリ「Apache POI」。この "POI" の正式名称は 「Poor Obfuscation Implementation(貧弱な難読化実装)」 です。
2000年代初頭、Officeフォーマットの仕様は非公開で、開発者たちはバイナリをリバースエンジニアリングするしかありませんでした。その複雑怪奇な構造への皮肉とフラストレーションが、そのままプロジェクト名になったのです。
その皮肉はモジュール名にも引き継がれています:
HSSF(Horrible Spreadsheet Format)= Excelを扱うAPIHWPF(Horrible Word Processor Format)= Wordを扱うAPIHSLF(Horrible Slide Layout Format)= PowerPointを扱うAPI
その後MicrosoftはOOXML(.docx/.xlsx)でXML化を進め、仕様も公開されましたが、本質は変わっていません。Officeフォーマットは「人間の視覚的な表示・印刷を最優先したアーキテクチャ」であり、「機械やAIが意味を抽出することを前提に設計されたもの」では根本的にないのです。
実装手順:Docs as CodeでMarkdownをCI/CDに組み込む
Markdownへの移行は、GitとAI連携の改善だけにとどまりません。「Docs as Code」の実践により、ドキュメントがコードと同じパイプラインで管理できるようになります。
全体像は次のような流れです。開発者がMarkdownをPush/PRすると、GitHub Actionsがtextlintで品質を検査し、MkDocsでサイトをビルドして公開します。

ステップ1: MkDocsでドキュメントポータルを構築する
pip install mkdocs-material
mkdocs new docs-site
cd docs-site
# mkdocs.yml
site_name: 開発ドキュメント
theme:
name: material
language: ja
nav:
- ホーム: index.md
- 設計: design/
- API仕様: api/
mkdocs serve # ローカルでプレビュー
ステップ2: GitHub ActionsでMainへのマージ時に自動デプロイ
# .github/workflows/deploy-docs.yml
name: Deploy Docs
on:
push:
branches: [main]
paths: ["docs/**"]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v4
with:
python-version: "3.x"
- run: pip install mkdocs-material
- run: mkdocs gh-deploy --force
これでdocs/以下のMarkdownを更新してmainにマージした瞬間、自動でドキュメントサイトが更新されます。「最新版はどれか」問題が消えます。
ステップ3: textlintで日本語の品質をCIで自動担保する
npm install -D textlint textlint-rule-preset-ja-technical-writing
{
"rules": {
"preset-ja-technical-writing": {
"no-mix-dearu-desumasu": true,
"sentence-length": { "max": 100 }
}
}
}
# CIに追加
- name: Lint docs
run: npx textlint docs/**/*.md
「です・ます調」と「だ・である調」の混在、表記ゆれ、リンク切れをCIで自動検知できます。レビューで毎回同じ指摘をしていた手間が消えます。
ハマりポイントと解決策
| 症状 | 原因 | 解決策 |
|---|---|---|
| 既存のdocxをMarkdownに変換したら表が崩れた | Pandocだけでは複雑な結合セルを再現しきれない | $ pandoc -f docx -t gfmで変換する。操作: 表はVS CodeのMarkdown All in OneやTableConvertで整える |
| textlintで誤検知が多発する | ルールプリセットがドキュメント種別と合っていない | 設定: .textlintrcでtextlint-rule-preset-ja-technical-writingのルールを個別にOFF/ONする |
| 表記ゆれをレビューで毎回指摘している | 辞書化されていない用語が人手レビューに残っている | $ npm install -D textlint-rule-prhを追加する。設定: prh.ymlで表記ルールを管理する |
| 見出し階層や箇条書きの崩れに気づけない | Markdown構文のスタイルチェックがない | $ npm install -D markdownlint-cli2を実行する。CI設定: npx markdownlint-cli2 docs/**/*.mdを追加する |
| LLMに渡してもWordと処理精度が変わらない | 変換後にHTMLコメントやスタイル残骸が残っている | 操作: VS Codeで<!--やstyle=を検索し、不要ブロックを削除してからLLMに渡す |
| GitHubでMathの数式が崩れる | GitHub独自のMath記法を使っていない | 書き方: インライン数式は$...$、ブロック数式は$$...$$に統一する。確認: GitHubプレビューで崩れないか確認する |
まとめ
.docx/.xlsxはGitのDiff・マージ・インラインレビューを根本的に阻害するバイナリフォーマット- LLMに渡すとXMLメタデータがコンテキストを浪費し、コスト増・精度低下を招く
- Apache POIの命名(HSSF = Horrible Spreadsheet Format)が示す通り、Officeフォーマットは機械処理向けに設計されていない
- MarkdownはSSGとCI/CDで「Docs as Code」を実現し、textlintで品質を自動担保できる
おわりに
実際に移行してみると、PRでドキュメントをインラインレビューできる体験は思った以上に快適で、「なんでもっと早くやらなかったんだろう」というのが率直な感想です。全部一度にやらなくていいので、まず新規ドキュメント1つからMarkdownで書いてみてください。きっと同じように感じるはずです。
参考資料
付録:トークン計測スクリプト
本記事のグラフは以下のスクリプトで生成しています。手元でも再現できます。
事前準備
pip install tiktoken matplotlib numpy
token_benchmark.py
import warnings
warnings.filterwarnings("ignore")
import matplotlib
matplotlib.use("Agg") # 画面表示なしでPNG保存
import tiktoken
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
# ── 1. 検証用サンプルコンテンツ ──────────────────────────────────────────
# 実際の開発ドキュメントを模した「ユーザー認証設計書」の一節
CONTENT_PLAIN = """
ユーザー認証設計
概要
本ドキュメントでは、会員管理システムにおけるユーザー認証の設計を定義する。
認証方式
JWT(JSON Web Token)を採用する。トークンの有効期限はアクセストークンが15分、リフレッシュトークンが7日間とする。
エンドポイント一覧
POST /api/auth/login - ログイン
POST /api/auth/refresh - トークン更新
DELETE /api/auth/logout - ログアウト
エラーコード
401 - 認証失敗(メールアドレスまたはパスワード不一致)
403 - アクセス権限なし
429 - レートリミット超過(1分間に10回まで)
セキュリティ要件
パスワードはbcryptでハッシュ化する(コストファクター: 12)。
ログイン失敗5回でアカウントを15分間ロックする。
"""
CONTENT_MARKDOWN = """
# ユーザー認証設計
## 概要
本ドキュメントでは、会員管理システムにおけるユーザー認証の設計を定義する。
## 認証方式
**JWT(JSON Web Token)** を採用する。トークンの有効期限は以下の通り。
| トークン種別 | 有効期限 |
|---|---|
| アクセストークン | 15分 |
| リフレッシュトークン | 7日間 |
## エンドポイント一覧
| メソッド | パス | 説明 |
|---|---|---|
| POST | `/api/auth/login` | ログイン |
| POST | `/api/auth/refresh` | トークン更新 |
| DELETE | `/api/auth/logout` | ログアウト |
## エラーコード
- `401` - 認証失敗(メールアドレスまたはパスワード不一致)
- `403` - アクセス権限なし
- `429` - レートリミット超過(1分間に10回まで)
## セキュリティ要件
- パスワードは **bcrypt** でハッシュ化する(コストファクター: 12)
- ログイン失敗5回でアカウントを **15分間** ロックする
"""
# 実際の .docx 内部 XML(OOXML)を模したサンプル
CONTENT_OOXML = """<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas"
xmlns:cx="http://schemas.microsoft.com/office/drawing/2014/chartex"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml"
xmlns:w16cid="http://schemas.microsoft.com/office/word/2016/wordml/cid"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
mc:Ignorable="w14 w16cid">
<w:body>
<w:p>
<w:pPr>
<w:pStyle w:val="Heading1"/>
<w:jc w:val="left"/>
<w:rPr>
<w:rFonts w:ascii="MS Gothic" w:hAnsi="MS Gothic" w:eastAsia="MS Gothic"/>
<w:sz w:val="32"/>
<w:szCs w:val="32"/>
<w:lang w:val="ja-JP" w:eastAsia="ja-JP"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="MS Gothic" w:hAnsi="MS Gothic" w:eastAsia="MS Gothic"/>
<w:sz w:val="32"/>
<w:lang w:val="ja-JP" w:eastAsia="ja-JP"/>
</w:rPr>
<w:t>ユーザー認証設計</w:t>
</w:r>
</w:p>
<w:p>
<w:pPr>
<w:pStyle w:val="Normal"/>
<w:jc w:val="left"/>
<w:spacing w:line="360" w:lineRule="auto"/>
<w:rPr>
<w:rFonts w:ascii="MS Mincho" w:hAnsi="MS Mincho" w:eastAsia="MS Mincho"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
<w:lang w:val="ja-JP"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="MS Mincho" w:hAnsi="MS Mincho" w:eastAsia="MS Mincho"/>
<w:sz w:val="24"/>
<w:lang w:val="ja-JP"/>
</w:rPr>
<w:t xml:space="preserve">本ドキュメントでは、会員管理システムにおけるユーザー認証の設計を定義する。</w:t>
</w:r>
</w:p>
<w:p>
<w:pPr>
<w:pStyle w:val="Normal"/>
<w:spacing w:line="360" w:lineRule="auto"/>
<w:rPr>
<w:rFonts w:ascii="MS Mincho" w:hAnsi="MS Mincho" w:eastAsia="MS Mincho"/>
<w:sz w:val="24"/>
<w:lang w:val="ja-JP"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="MS Mincho" w:hAnsi="MS Mincho" w:eastAsia="MS Mincho"/>
<w:sz w:val="24"/>
<w:b/>
<w:lang w:val="ja-JP"/>
</w:rPr>
<w:t xml:space="preserve">JWT(JSON Web Token)</w:t>
</w:r>
<w:r>
<w:rPr>
<w:rFonts w:ascii="MS Mincho" w:hAnsi="MS Mincho" w:eastAsia="MS Mincho"/>
<w:sz w:val="24"/>
<w:lang w:val="ja-JP"/>
</w:rPr>
<w:t xml:space="preserve"> を採用する。トークンの有効期限はアクセストークンが15分、リフレッシュトークンが7日間とする。</w:t>
</w:r>
</w:p>
<w:sectPr>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440"/>
</w:sectPr>
</w:body>
</w:document>"""
# ── 2. トークン計測 ───────────────────────────────────────────────────────
enc = tiktoken.get_encoding("cl100k_base") # GPT-4 / GPT-3.5-turbo 同等
plain_tokens = len(enc.encode(CONTENT_PLAIN))
md_tokens = len(enc.encode(CONTENT_MARKDOWN))
ooxml_tokens = len(enc.encode(CONTENT_OOXML))
content_tokens = plain_tokens # プレーンテキストをコンテンツトークンの基準とする
md_noise = md_tokens - content_tokens
ooxml_noise = ooxml_tokens - content_tokens
print("=" * 50)
print("【検証結果】同一内容の3フォーマットのトークン数")
print("=" * 50)
for label, tokens in [
("プレーンテキスト", plain_tokens),
("Markdown", md_tokens),
("OOXML (docx内部XML)", ooxml_tokens),
]:
print(f"{label:25s}: {tokens:>5} tokens ({tokens / plain_tokens:.1f}x)")
print()
print(f"SNR (Markdown): {content_tokens / md_tokens * 100:.1f}%")
print(f"SNR (OOXML): {content_tokens / ooxml_tokens * 100:.1f}%")
# ── 3. グラフ生成 ─────────────────────────────────────────────────────────
plt.rcParams["font.family"] = ["Hiragino Sans", "sans-serif"]
plt.rcParams["axes.unicode_minus"] = False
fig, axes = plt.subplots(1, 2, figsize=(13, 6))
fig.suptitle(
"Markdown vs OOXML:LLMトークン消費量の実測比較\n(同一内容・tiktoken cl100k_base 使用)",
fontsize=13, fontweight="bold", y=1.01,
)
labels = ["プレーンテキスト", "Markdown", "OOXML\n(docx内部XML)"]
total_t = [plain_tokens, md_tokens, ooxml_tokens]
noise_t = [0, md_noise, ooxml_noise]
content_t = [content_tokens] * 3
# グラフ①:積み上げ棒グラフ
ax1 = axes[0]
x = np.arange(len(labels))
ax1.bar(x, content_t, color="#5B8DB8", zorder=3)
ax1.bar(x, noise_t, bottom=content_t, color=["#E0E0E0", "#A8D5A2", "#F4A261"], zorder=3)
ax1.set_xticks(x)
ax1.set_xticklabels(labels, fontsize=10)
ax1.set_ylabel("トークン数", fontsize=11)
ax1.set_title("① トークン内訳(コンテンツ vs 書式メタデータ)", fontsize=11, pad=10)
ax1.grid(axis="y", linestyle="--", alpha=0.5, zorder=0)
ax1.set_axisbelow(True)
for i, total in enumerate(total_t):
ax1.text(i, total + 10, f"{total} tokens", ha="center", va="bottom",
fontsize=10, fontweight="bold")
ax1.legend(handles=[
mpatches.Patch(color="#5B8DB8", label="コンテンツ(意味情報)"),
mpatches.Patch(color="#F4A261", label="オーバーヘッド(書式メタデータ)"),
], loc="upper left", fontsize=9)
# グラフ②:SNR 横棒グラフ
ax2 = axes[1]
snr_values = [100.0, content_tokens / md_tokens * 100, content_tokens / ooxml_tokens * 100]
bars_snr = ax2.barh(labels, snr_values, color=["#5B8DB8", "#5BAD6B", "#E8734A"], zorder=3)
ax2.set_xlim(0, 115)
ax2.set_xlabel("SNR(意味情報の割合)%", fontsize=11)
ax2.set_title("② Signal-to-Noise Ratio(SNR)\n高いほどLLMが効率よく情報を読める", fontsize=11, pad=10)
ax2.grid(axis="x", linestyle="--", alpha=0.5, zorder=0)
ax2.set_axisbelow(True)
ax2.invert_yaxis()
for bar, val in zip(bars_snr, snr_values):
ax2.text(val + 1.5, bar.get_y() + bar.get_height() / 2,
f"{val:.1f}%", va="center", fontsize=11, fontweight="bold")
ax2.axvline(x=100, color="gray", linestyle=":", alpha=0.4)
fig.tight_layout(pad=2.0)
fig.savefig("token_benchmark.png", dpi=150, bbox_inches="tight")
print("\nグラフを保存しました: token_benchmark.png")







