はじめに
デジタルエンジニアリング部の松本です。
前回の記事では、Claude Codeの暴走を止めるためにhooksを「外部への最終関所」として置いている、というところまでをざっくりとお話ししました。
今回はそのうちの1本、guard-secrets.mjs を題材にして、設計の意図と実装を最後まで読み解いていきます。
想定する読者は以下のとおりです。
- Claude Codeでhookを書こうとしている、あるいは導入を検討しているエンジニア
- AIエージェントがコード中にAPIキーを混入させた経験がある、またはそのリスクを潰したい方
- 「PreToolUse hookで結局なにを返せばツール実行を止められるのか」を知りたい方
結論を先に置きます。
secret漏洩への防御は層で組む。本筋はpermissionsで「そもそも読ませない」こと。
本記事のguard-secrets.mjsは、その本筋が破られた最悪のケースに備える「最終関門」のhookである。
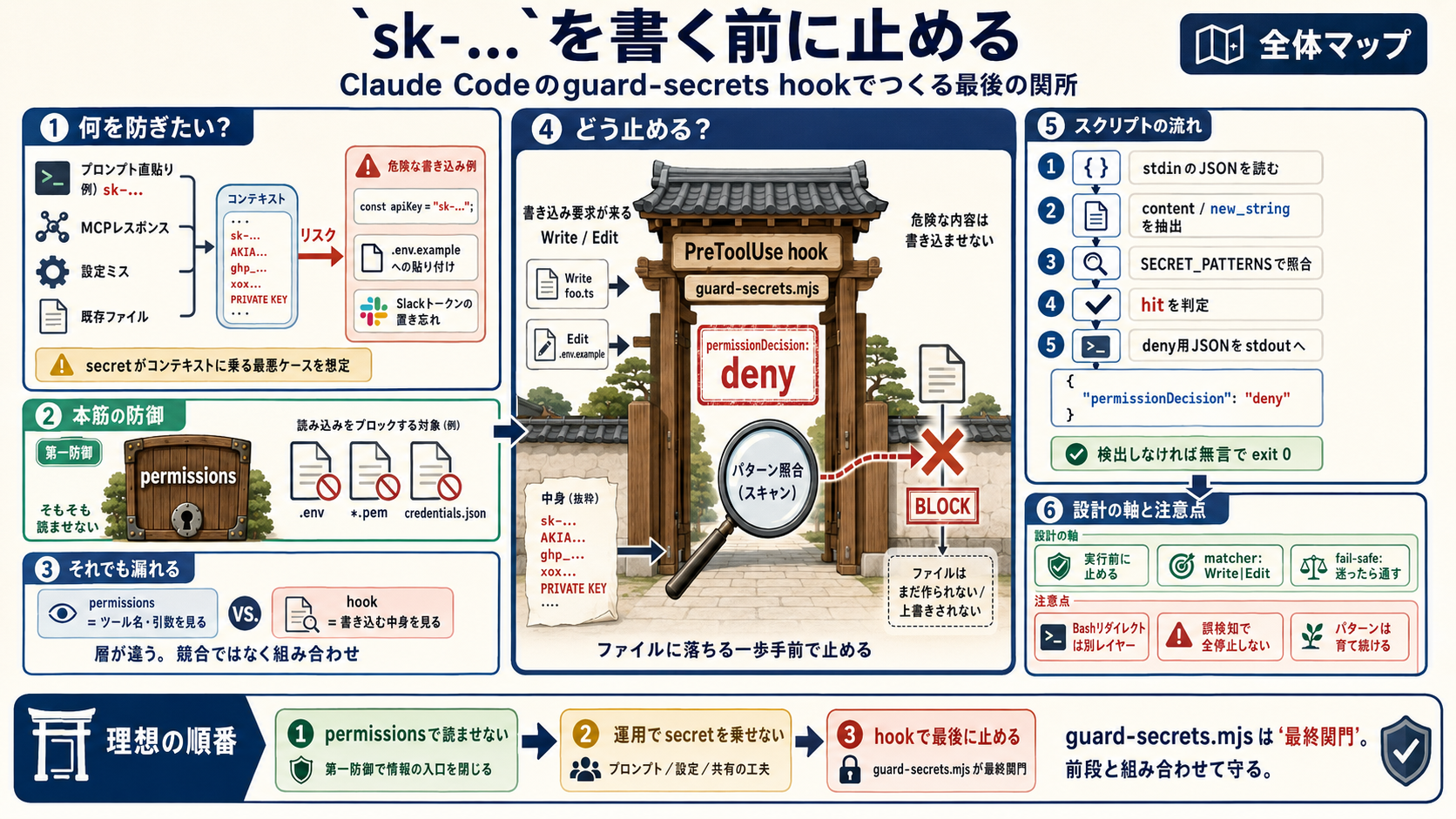
ここでいう「最終関門」とは、Claude CodeがWriteやEditツールを実行する直前のことです。
本記事で扱うguard-secrets.mjsは、その瞬間に書き込み内容を検査し、secretパターンが含まれていたらツール実行を拒否するPreToolUse hookです。
前段の防御をすべて素通りしてしまったsecretを、ファイルに落ちる一歩手前で止める役回りになります。
なお、本記事のコードや設計判断は2026年5月時点のClaude Code仕様に基づきます。
仕様変更があれば本文の前提も変わる点はあらかじめご了承ください。
解こうとしている問題
まず大原則を置きます。
AIエージェントには、そもそもsecretを見せない・知らせないのが本筋です。
推奨される第一防御は、permissionsで.envや*.pem、credentials.jsonなどへの読み取りそのものを禁じることです。
エージェントがsecretを「知らない」状態を維持できれば、その後の漏洩経路はまとめて閉じられます。
ただし、現実の運用では第一防御だけで完封するのは難しい場面があります。
- ユーザーがプロンプトに直接
sk-...を貼り付けてしまう - MCPサーバーやサードパーティツールのレスポンスにトークンが混ざる
- 設定ミスや読み取り許可の漏れで、想定外のファイルからsecretが読まれる
- 既存ファイルに残ったsecretを、Editで触ったついでにAIが目にする
第一防御の網を密にする努力は当然したうえで、それでもsecretがコンテキストに乗ってしまう瞬間は起こり得る——その最悪のケースを想定して2段目を用意しておきたいです。
本記事のguard-secrets.mjsは、その2段目=ファイルに落ちる一歩手前で止める最終関門です。
そのうえで、Write/Editの直前で止めたい具体的な事故は以下のようなものになります。
- AIがサンプルコードを書こうとして
const apiKey = "sk-...";をそのままファイルに保存する .envの中身をうっかり.env.exampleに貼り付ける- デバッグ用にハードコードしたSlackトークンを、コミット直前に削除し忘れる
前回紹介した三者分離(Planner/Executor/Reviewer)を回していても、Reviewerがdiffの隅々まで目視するわけではありません。
正規表現で機械的に弾けるものは、機械で弾いてしまうほうが安全です。
ポイントは、「書かれてしまった後」より「書く前」に止めたい、というところです。
一度ファイルに落ちると、ローカルのGitに紛れ込んだり、Claude Codeのバックアップ機構やシェル履歴にコピーが残ったりします。
書き出すツールが発火する直前で止めるのが、最も影響範囲を小さくできる地点になります。
「permissionsで防げないのか」という疑問
ここで素朴な疑問が出てきます。
「permissionsで.envの読み取りを禁じておけば、そもそもAIがsecretを知らないのではないか。」
これは半分正解です。
前節で触れたとおり、読み取りそのものを止めるのが第一防御で、permissionsはまさにそのために使う仕組みです。.envや鍵ファイルへのReadを拒否しておけば、エージェントがsecretを「知る」経路の大半は閉じられます。
ただし、permissionsだけでは塞ぎきれない経路が残ります。
プロンプトへの直接貼り付け・MCPレスポンス・読み取り許可の漏れ・既存ファイルからの不意な読み込みなど、secret がコンテキストに乗ってしまう穴は完全には消えません。
permissionsはあくまでツール名 + 引数(パスやコマンド先頭)のパターンマッチで動きます。
「Readで.envを読むのは禁止」のような制御は得意ですが、コンテキストに乗ってしまったsecretが今まさに書き出されようとしているかは、permissionsからは見えません。
一方、guard-secretsが見たいのはWrite/Editで書き込もうとしているファイルの中身そのものです。WriteのcontentやEditのnew_stringにsk-...が含まれているかどうかを、任意の正規表現で照合したい。
これはpermissionsの表現範囲を超えます。
| 仕組み | 役割 | 守るタイミング |
|---|---|---|
| permissions | エージェントにそもそも読ませない・実行させない第一防御 | ツール呼び出しが許可されるかどうか |
| PreToolUse hook | コンテキストに乗ってしまったsecretを書き出させない最終関門 | ツール実行の直前 |
つまりpermissionsとhookは競合する仕組みではなく、層が違う仕組みです。
理想は両者を組み合わせること。.envや*.pemのReadはpermissionsで止め、それでもsecretがコンテキストに乗ってしまった最悪のケースの書き出しはhookで止める。
guard-secrets.mjsは、その最終関門としてのhookです。前段が完璧であれば発火しないのが理想ですが、その前提が崩れた瞬間に最後のひと押しで止める役回りになります。
guard-secrets.mjsの設計3つの軸
実装の話に入ります。
設計上の判断は、以下の3つに集約されます。
軸1. PreToolUseで「実行前」に止める
Write/Editが実行された後で消すのではなく、実行する前にdenyを返して、そもそも書き出させません。
ファイル・シェル履歴・gitのどこにもsecretが残らない設計です。
軸2. matcherをWrite|Editに絞る
.claude/settings.json側でmatcher: "Write|Edit"として、書き込み系ツールにだけhookを噛ませます。
本来はBashのecho "..." > fileのようなリダイレクト書き込みも対象にしたいところです。
ただし全Bashコマンド × secret正規表現は誤検知とパフォーマンス悪化のコストが大きいため、現状はBashカバー外を許容しています(Bash経由の外部アクションは別hookで補完)。
軸3. fail-safeで「迷ったら通す」
JSON入力が壊れていたり、想定外のフィールド構造だったりした場合は、ブロックせずに素通しします。
検査機構の不調でAIの作業全体が止まると、生産性のダメージのほうが大きいからです。
secret検査用のhookは、「疑わしきは通す」を貫いたほうが結果として運用が安定します。
スクリプト本体
実装はコメントを除けば50行ほどで収まります。本文に丸ごと貼ります。
#!/usr/bin/env node
import { readFileSync } from 'fs';
// Step 1: stdinからJSONを受け取る(壊れていたら素通し)
let input = {};
try {
input = JSON.parse(readFileSync(0, 'utf8'));
} catch {
process.exit(0);
}
// Step 2: 検査対象の文字列を抽出
const ti = input.tool_input || {};
const content = ti.content || ti.new_string || '';
// Step 3: 「漏れたら危険な秘密情報」のパターン定義
const SECRET_PATTERNS = [
/sk-[a-zA-Z0-9-]{32,}/, // OpenAI / Stripe
/sk-ant-[a-zA-Z0-9_-]{20,}/, // Anthropic
/AKIA[0-9A-Z]{16}/, // AWS Access Key ID
/xox[baprs]-[0-9a-zA-Z-]{10,}/, // Slackトークン
/-----BEGIN (RSA |EC |DSA |OPENSSH |)PRIVATE KEY-----/, // PEM秘密鍵
/ghp_[A-Za-z0-9]{36,}/, // GitHub PAT
/gho_[A-Za-z0-9]{36,}/, // GitHub OAuth
/glpat-[A-Za-z0-9_-]{20,}/, // GitLab PAT
/https:\/\/discord(?:app)?\.com\/api\/webhooks\/\d{17,19}\/[\w-]{60,}/, // Discord webhook
/AIza[0-9A-Za-z_-]{35}/, // Google APIキー
/sk_live_[a-zA-Z0-9]{24,}/, // Stripe Live secret key
];
// Step 4: パターン照合
const hit = SECRET_PATTERNS.find((pattern) => pattern.test(content));
// Step 5: 結果をClaude Codeに返す
if (hit) {
process.stdout.write(
JSON.stringify({
hookSpecificOutput: {
hookEventName: 'PreToolUse',
permissionDecision: 'deny',
permissionDecisionReason: `Secret pattern detected: ${hit.source.slice(0, 40)}...`,
},
})
);
}
process.exit(0);
注目すべきはStep 2とStep 5です。
Step 2では、ツール種別によって書き込み本文の格納フィールド名が違うのを吸収しています。
Claude Codeの仕様ではWriteはcontent、Editはnew_stringに本文が入ります。
2つを順に見て、最初に値が入っているものを採用するシンプルな書き方です。
Step 5は、hookがClaude Codeに「拒否してくれ」と伝えるためのプロトコル部分です。次節で詳しく見ていきます。
permissionDecision: denyはどう動くのか
Claude CodeのPreToolUse hookは、stdoutに特定の構造のJSONを出すことでツール実行を制御できます。
今回のhookでは以下のJSONを出力しています。
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": "Secret pattern detected: ..."
}
}
要点は以下のとおりです。
permissionDecisionに'deny'を入れると、Claude Codeはそのツール実行を取り消すpermissionDecisionReasonはAIから読める形で残るので、AIは「なぜ止められたか」を理解して次の行動(環境変数読み出しへの書き換えなど)を選べる- 検出しなかったときは何も出力せず
exit 0でOK。hookは「黙って素通り」をデフォルト挙動にできる
つまりhookの返却プロトコルは「通すなら無言、止めるならJSON」というシンプルな約束ごとに尽きます。
最初に押さえてしまうと、以降の実装はずいぶん見通しがよくなります。
触ってわかった注意点
実運用しながら気づいた、見落としやすいポイントを3つ挙げておきます。
1. Bashリダイレクトはカバー外
冒頭で触れたとおり、echo "OPENAI_API_KEY=sk-..." > .envのようにBash経由でファイルに書き込むケースは、Write|Editのmatcherには引っかかりません。
これは仕様上の制約として割り切ったうえで、外部アクションを別レイヤーで止めるhookを併走させて補完しています。
完璧を狙わず、層で守る発想です。
2. 誤検知でブロックしない
try/catchで壊れたJSONを素通しさせているのは意図的です。
secret検査機構の不調でAIの全作業を止めると、生産性損失のほうが大きくなってしまいます。
「疑わしきは通す」のほうが、検査hookとしての設計としては正しいケースが多いと感じます(もちろん対象によります)。
3. パターンは「足し続ける」前提
正規表現リストは育てる前提のものです。
手元のhookも、当初はOpenAI / AWS / Slack / GitHub / PEM秘密鍵あたりから始まりました。
運用を重ねるなかで、Discord webhook、Google APIキー、Stripe Live secretなどを徐々に追加してきています。
hookは書いて終わりではなく、ヒヤリハットのたびに1行ずつ育てていく成長物として持っておくと、運用の手応えがあります。
おわりに
guard-secrets.mjsは本体50行ほどの小さなhookです。
それでも、PreToolUse hook設計の基本パターンが3つきれいに詰まっています。
- ファイルの中身を覗いて弾く
- 書く瞬間に止める
- 黙って素通すか、JSONで止めるか
初めてPreToolUse hookを書く方にとって、コピペで動かしてみる教材としてちょうどよいサイズと言えます。
ただし最後に強調しておきたいのは、このhookは最終関門であって最初の防御ではない、という点です。
理想は次の順番で層を組むことです。
permissionsで.envや鍵ファイルなどの読み取りそのものを禁じる(エージェントにsecretを知らせない)- プロンプトに直接secretを貼らない・MCP連携先のレスポンスを精査するなど、運用面でコンテキストにsecretが乗らないようにする
- それでもコンテキストに乗ってしまった最悪のケースに備え、Write/Edit直前でこのhookが拾う
前段の1と2が本筋であり、本来であればこのhookが発火しないのが正しい状態です。
逆に、hookだけに頼って前段が疎かだと、Bashリダイレクトやログ出力など別の経路からsecretは出ていきます。
層の最後尾として置く、という位置づけが大事です。
最後に、前回記事で立てたメッセージを少しだけ拡張して締めます。
AIエージェントを「育てる」ためには、仕組みも一緒に育てる必要がある。
hookは派手な機能ではありませんが、最終関門として設けておくと、前段で取りこぼした最悪のケースを足元で受け止められます。皆さんの環境にも、最小1本から仕込んでみてはいかがでしょうか。