


こんにちは!
9月入社、デジタルエンジニアリング部 SE課 4G 菅野です。
今回はSQLの中でも知っていると得するかもしれない「ウィンドウ関数」についてのテックブログです。
ちょっと難しそう...と思うかもしれませんが、累積計算やランキングなどに役立つ便利な関数です。
ウィンドウ関数を学んで、SQLの楽しみを広げましょう!
対象読者
- SQLの基本的な構文はわかったぞ!という方
- ウィンドウ関数を使ったことがない方
- ウィンドウ関数の使い方を知りたい方
パーティションとは
ウィンドウ関数の中でよく出てくるのが、PARTITION BY です。
これは「データをどの単位で区切って集計するか」を指定するものです。
例:
-
PARTITION BY store_name
→ 店舗ごとに区切って、各店舗ごとに累積やランキングを計算する -
PARTITION BY product_name
→ 商品ごとに区切って、商品の売上推移を分析する
「パーティション=分析単位のグループ」と考えるとわかりやすいと思います!
「GROUP BY」と「PARTITION BY」の違いについて
ウィンドウ関数に入る前に、まずは「GROUP BY」と「PARTITION BY」の違いを整理します。
両者とも「指定の区分ごとにレコードをまとめる」という点では共通していますが、そのまとめ方が異なります。
-
GROUP BY
→ 区分ごとに集約し、結果は「1行にまとめられる」 -
PARTITION BY
→ 区分ごとにグループ化するが、行は保持したままで、それぞれの行に対して集計結果を付与できる
つまり、
- GROUP BY → 「合計だけ見たいとき」
- PARTITION BY → 「合計を見つつ、行ごとの詳細も残したいとき」 という使い分けになります。
ざっくり図解
GROUP BYがAとBのレコードをそれぞれまとめにしてしまうのに対し、PARTITION BYはAとBを別々に認識しつつ、各行は認識できる状態です。
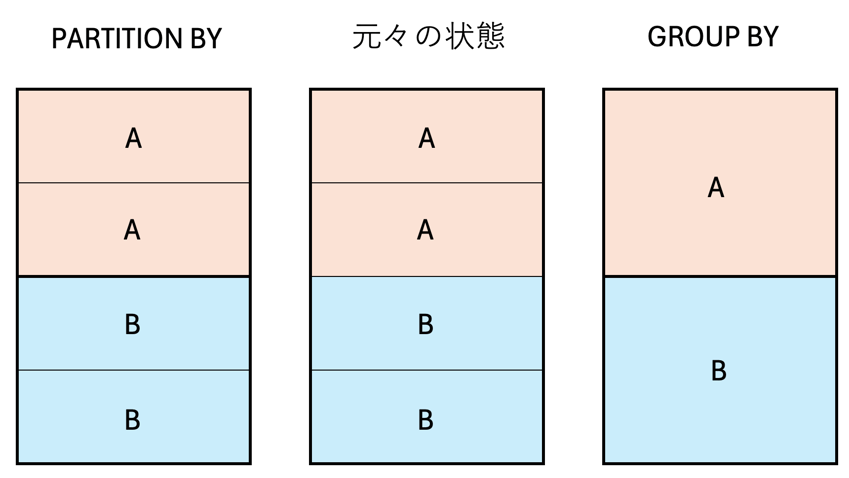
※画像:菅野作成
ウィンドウ関数とは
ウィンドウ関数は、PARTITION BYを利用して、レコードをパーティションで区切りつつ、各レコードを認識している状態で集計処理することができます。
パーティションとは、ウィンドウ関数を適用する際に、どの範囲のデータに対して計算を行うかを指定するために使われます。
for文でカーソルを当てながら処理していくイメージで良いと思います。
ウィンドウ関数を使うことにより、累積計算や移動平均、ランキングをつけたりなどが容易に行えるようになります。
ウィンドウ関数でよく使う関数の紹介
- 移動平均・統計
- SUM():パーティション内で累計を計算する
- AVG():移動平均や全体平均
- MAX() / MIN():パーティション内での最大値、最小値
- 集計
- ROW_NUMBER():パーティション内で行に連番を振る(重複なし)
- RANK():順位を振る(同順位があれば次の順位が飛ぶ)
- DENSE_RANK():順位を振る(同順位があっても順位が飛ばない)
ウィンドウ関数の注意点
便利なウィンドウ関数ですが、大きなデータを扱うときは注意も必要です。
- ソート処理が必須になることが多い
- ORDER BYを伴うウィンドウ関数はパーティションごとにソートされる
- 特にパーティションごとに合計を出す「SUM(…) OVER(PARTITON BY … ORDER BY …)」やパーティションごとのランキングを出す「RANK()」は、ソートが計算コストの中心になる
- データ件数が多くなると、ソートがボトルネックになりやすい
- → ソート対象の列にインデックスを貼ると改善できる
- パーティション分割数が多いと重くなる
- PARTITION BYは「区切りごとに処理を独立して実行」するため、区切りの数が多いとその分時間がかかる
- → 事前に集約した一時テーブルを作ると改善できる
- フレーム指定(ROWSやRANGE)は慎重に
- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWは累積処理には便利だが、広範囲になると処理が重くなる
- どうしても必要な場合は、フレームの範囲を小さくする(例:移動平均ならROWS 2 PRECEDING程度にしておくなど)
- メモリ消費に注意
- ウィンドウ関数は「パーティション単位での結果セットを一時的に保持」することが多い
- 特にRANKのようなソート+保持はメモリ消費量が大きい
- 対策としては、大規模なデータは、一気に処理せず期間ごとに分けて実行するなどできる(例:月ごと、店舗ごと)
サンプルクエリの紹介
サンプル:売上を管理するテーブルを想定
CREATE TABLE Sales (
store_name VARCHAR(100) NOT NULL,
product_name VARCHAR(100) NOT NULL,
amount INT NOT NULL,
sale_date DATE NOT NULL
);
INSERT INTO Sales (store_name, product_name, amount, sale_date)
VALUES
('Tokyo', 'Apples', 1200, '2024-10-01'),
('Tokyo', 'Bananas', 800, '2024-10-03'),
('Tokyo', 'Oranges', 1500, '2024-10-05'),
('Osaka', 'Apples', 600, '2024-10-02'),
('Osaka', 'Bananas', 700, '2024-10-03'),
('Osaka', 'Oranges', 900, '2024-10-06'),
('Osaka', 'Apples', 1000, '2024-10-08');
GROUP BYで店舗ごとに合計を求める
SELECT store_name,
SUM(amount) AS total_sales
FROM Sales
GROUP BY store_name;| store_name | total_sales |
|---|---|
| Osaka | 3200 |
| Tokyo | 3500 |
店舗ごとの累積売上を見たい!
例:店舗ごとに日付順に並べて、その時点までの累積売上を出す
SELECT store_name,
sale_date,
amount AS daily_sales,
SUM(amount) OVER(PARTITION BY store_name ORDER BY sale_date) AS cum_sales
FROM Sales;
| store_name | sale_date | daily_sales | cum_sales |
|---|---|---|---|
| Osaka | 2024-10-02 | 600 | 600 |
| Osaka | 2024-10-03 | 700 | 1300 |
| Osaka | 2024-10-06 | 900 | 2200 |
| Osaka | 2024-10-08 | 1000 | 3200 |
| Tokyo | 2024-10-01 | 1200 | 1200 |
| Tokyo | 2024-10-03 | 800 | 2000 |
| Tokyo | 2024-10-05 | 1500 | 3500 |
店舗ごとの商品売上ランキングを出したい!
SELECT store_name,
product_name,
amount,
RANK() OVER(PARTITION BY store_name ORDER BY amount DESC) AS ranking
FROM Sales;
RANK()はランキング付けすることができる関数
| store_name | product_name | amount | ranking |
|---|---|---|---|
| Osaka | Apples | 1000 | 1 |
| Osaka | Oranges | 900 | 2 |
| Osaka | Bananas | 700 | 3 |
| Osaka | Apples | 600 | 4 |
| Tokyo | Oranges | 1500 | 1 |
| Tokyo | Apples | 1200 | 2 |
| Tokyo | Bananas | 800 | 3 |
店舗ごとの商品の売上割合を見たい!
SELECT store_name,
product_name,
amount,
ROUND(
amount * 100.0 / SUM(amount) OVER(PARTITION BY store_name), 2
) AS sales_ratio
FROM Sales;
| store_name | product_name | amount | sales_ratio |
|---|---|---|---|
| Osaka | Apples | 600 | 18.75 |
| Osaka | Bananas | 700 | 21.88 |
| Osaka | Oranges | 900 | 28.13 |
| Osaka | Apples | 1000 | 31.25 |
| Tokyo | Apples | 1200 | 34.29 |
| Tokyo | Bananas | 800 | 22.86 |
| Tokyo | Oranges | 1500 | 42.86 |
短期的なトレンドを追いたい!
「ROWS BETWEEN 2 PRECEDING AND CURRENT ROW」で前2行と今の行を処理することを示しています。
SELECT store_name,
sale_date,
amount AS daily_sales,
ROUND(
AVG(amount) OVER(
PARTITION BY store_name
ORDER BY sale_date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
), 2
) AS moving_avg
FROM Sales;
| store_name | sale_date | daily_sales | moving_avg |
|---|---|---|---|
| Osaka | 2024-10-02 | 600 | 600.00 |
| Osaka | 2024-10-03 | 700 | 650.00 |
| Osaka | 2024-10-06 | 900 | 733.33 |
| Osaka | 2024-10-08 | 1000 | 866.67 |
| Tokyo | 2024-10-01 | 12000 | 1200.00 |
| Tokyo | 2024-10-03 | 800 | 1000.00 |
| Tokyo | 2024-10-05 | 1500 | 1166.67 |
まとめ
今回の記事では、ウィンドウ関数を通して以下のポイントを学びました。
-
GROUP BYとPARTITION BYの違い
-
GROUP BY → グループごとに1行にまとめて集計する
-
PARTITION BY → グループごとに区切りつつ、行を保持したまま集計結果を付与できる
→ 「全体をまとめたいのか、それとも行を残したまま分析したいのか」で使い分ける
-
-
ウィンドウ関数でできること
- 累積計算(累積売上の推移を確認)
- ランキング(店舗ごとの売上順位を付与)
- 割合計算(全体に対する各行の割合を算出)
- 移動平均(短期的なトレンドを把握)
- 差分計算(前日比・成長率なども可能)
-
パフォーマンスの注意点
- ソート処理やパーティション分割が重くなりやすい
- インデックスの利用やフレーム範囲の工夫で最適化できる
- 大規模データでは一時テーブルや期間分割で対応する
GROUP BYが「まとめて終わり」なら、PARTITION BYを使ったウィンドウ関数は「まとめつつ分析を続けられる」強力なツールです。
ちょっと気味が悪かったOVER(…)の構文も、
「区切る(PARTITION)」「並べる(ORDER)」「カーソルで処理する(OVER)」という流れを意識すれば自然に理解できます。
SQLをデータ抽出だけで終わらせず、分析や可視化する集計を深めたいときにぜひ使ってみてください!
参考文献
最後までお読みいただき、ありがとうございました!!!







