

はじめに
クラウドインテグレーション部の渡邊です。
今回は、AWS Glueジョブのログ種別について説明します。
S3へ出力されるSparkUI(デフォルトの出力先s3://aws-glue-assets-XXXXXXXXXXXX-ap-northeast-1/sparkHistoryLogs/)のログや、
AWS Glue Crawler(デフォルトの出力先/aws-glue/crawlers)に関する記述はありませんので、ご了承ください。
ログ種別
以下のログを、Amazon CloudWatch Logsへ出力できます。
| ログ名 | CloudWatch Logs | 説明 | |
|---|---|---|---|
| Glue Job | AWS Glue ジョブのリアルタイム連続ログ | /aws-glue/jobs/logs-v2 | Apache Spark ジョブのログ |
| 標準出力ログ | /aws-glue/jobs/output | Glue Spark ジョブ実行時における標準出力ログ | |
| エラーログ | /aws-glue/jobs/error | Glue Spark ジョブ実行時におけるエラーログ | |
| AWS Glue Studio | Glue interactive session のエラーログ | /aws-glue/sessions/error | インタラクティブセッション使用時のエラーログ※1 |
※1 ログの命名およびセッション中に出力される点から記述してますが、該当のログの記述を公式ドキュメントから見つけられませんでした
後に共有する出力結果からもわかりますが、エラー系のログストリームには、エラー以外のログも出力されます。
Glue Jobのログ
AWS Glue ジョブ実行インサイトの例を参考に、CloudWatch Logsを出力します。
使用する、ジョブのスクリプトは以下の通りです。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import *
from pyspark.sql.functions import udf,col
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
data_set_1 = [1, 2, 3, 4]
data_set_2 = [5, 6, 7, 8]
scoresDf = spark.createDataFrame(data_set_1, IntegerType())
print(spark)
print("サンプルログです")
def data_multiplier_func(factor, data_vector):
import tensorflow as tf
with tf.compat.v1.Session() as sess:
x1 = tf.constant(factor)
x2 = tf.constant(data_vector)
result = tf.multiply(x1, x2)
return sess.run(result).tolist()
data_multiplier_udf = udf(lambda x:data_multiplier_func(x, data_set_2), ArrayType(IntegerType(),False))
factoredDf = scoresDf.withColumn("final_value", data_multiplier_udf(col("value")))
print(factoredDf.collect())
必要なモジュール(tensorflow)をインポートし忘れて、データを解析して機械学習モデルを構築してしまっている想定です。
途中で実行される以下処理が、標準出力として記録される想定です。
print(spark)
print("サンプルログです")
ログの確認
スクリプトをもとにジョブを実行すると、実行に失敗するはずです。
失敗したジョブの詳細を確認します。
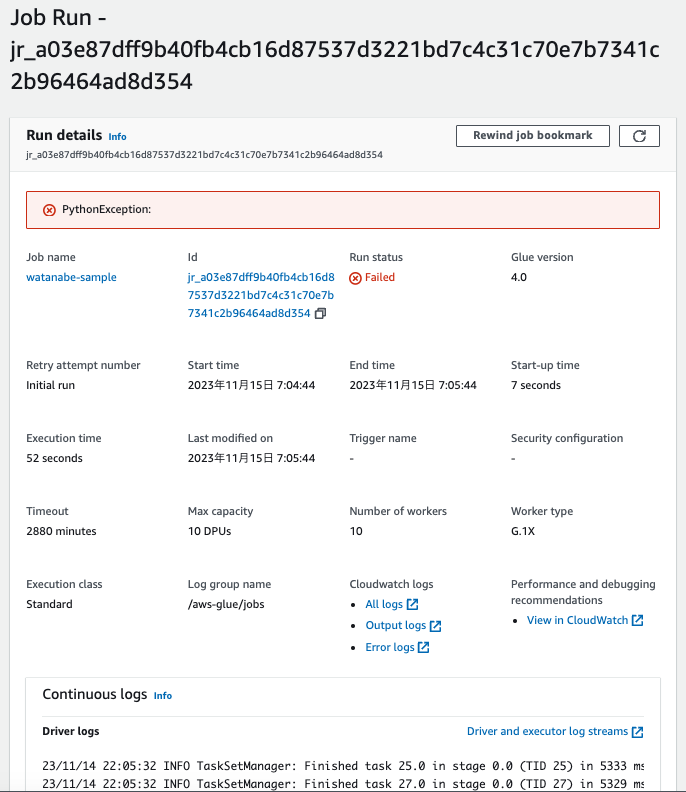
するとCloudWatch Logsにリンクが埋め込まれているので、それぞれクリックすると、ログを確認できます。
以降で、順番にログを確認します。
- All logs(/aws-glue/jobs/logs-v2)
- Output logs(/aws-glue/jobs/output)
- Error logs(/aws-glue/jobs/error)
AWS Glue ジョブのリアルタイム連続ログ(/aws-glue/jobs/logs-v2)
エグゼキュター(Executor)およびドライバー(Driver)単位で、ログストリームが出力されています。
エグゼキュターとは、タスク実行を担当するプロセスです。
ドライバーログ、エグゼキュターログ、および Apache Spark ジョブの進行状況バーを含む、Amazon CloudWatch のリアルタイムの Apache Spark ジョブログを表示できます。
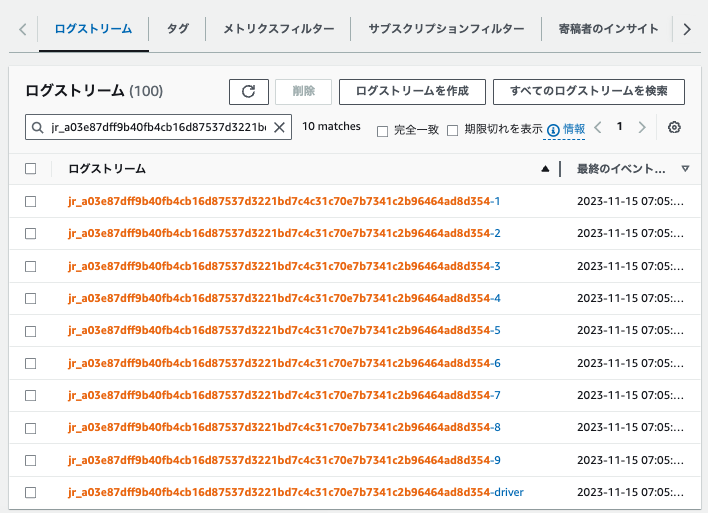
ログストリームの末尾の番号が、Executor IDと一致しています。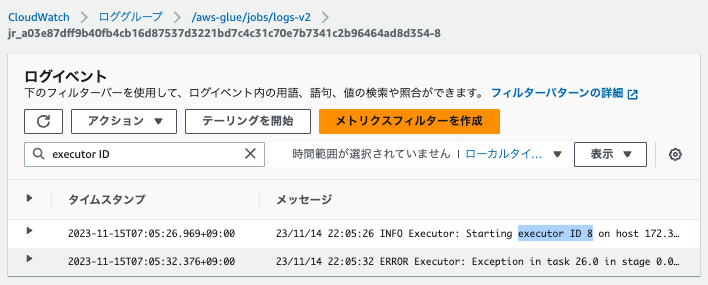
- エグゼキュターログの例
23/11/14 22:05:26 INFO Executor: Starting executor ID 8 on host XXX.XXX.XXX.XXX
AWS Glue ETL パフォーマンス・チューニング① 基礎知識編 p. 48を見ると、エグゼキュターログとドライバーログのストリームが出力される旨の記載がありました。
エラーログに絞って、ログを確認します。
いずれのログでも、同様のエラーが確認できました。
- ドライバーログの例
23/11/14 22:05:33 ERROR ProcessLauncher: Error from Python:Traceback (most recent call last):
File "/tmp/watanabe-sample.py", line 35, in <module>
print(factoredDf.collect())
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/dataframe.py", line 818, in collect
sock_info = self._jdf.collectToPython()
File "/opt/amazon/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1321, in __call__
return_value = get_return_value(
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 196, in deco
raise converted from None
pyspark.sql.utils.PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/tmp/watanabe-sample.py", line 33, in <lambda>
File "/tmp/watanabe-sample.py", line 26, in data_multiplier_func
ModuleNotFoundError: No module named 'tensorflow'
こちらでも同様に、エラーが確認できるログストリームと、そうでないログストリームがありました。
Executor IDが2,3,8のものがエラーログとしてヒットしています。
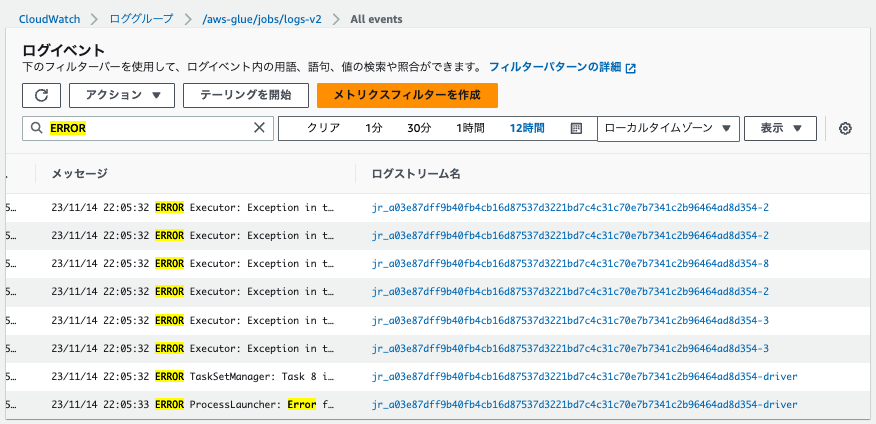
エグゼキュターログ
23/11/14 22:05:32 ERROR Executor: Exception in task 26.0 in stage 0.0 (TID 26)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/tmp/watanabe-sample.py", line 33, in <lambda>
File "/tmp/watanabe-sample.py", line 26, in data_multiplier_func
ModuleNotFoundError: No module named 'tensorflow'
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:559) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:86) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:68) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:512) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491) ~[scala-library-2.12.15.jar:?]
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460) ~[scala-library-2.12.15.jar:?]
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460) ~[scala-library-2.12.15.jar:?]
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) ~[?:?]
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:35) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.hasNext(Unknown Source) ~[?:?]
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:968) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:383) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:890) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.scheduler.Task.run(Task.scala:138) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548) ~[spark-core_2.12-3.3.0-amzn-1.jar:?]
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1516) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551) ~[spark-core_2.12-3.3.0-amzn-1.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_382]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_382]
標準出力ログ(/aws-glue/jobs/output)
同様に、CloudWatch Logsから確認すると、ログの出力が確認できました。
<pyspark.sql.session.SparkSession object at 0x7f8078345840>
サンプルログです
エラーログ(/aws-glue/jobs/error)
他のログと同様に確認すると、以下2パターンでログストリームが出力されています。
- タスク単位でのエラーログ
- ドライバーにおけるエラーログ
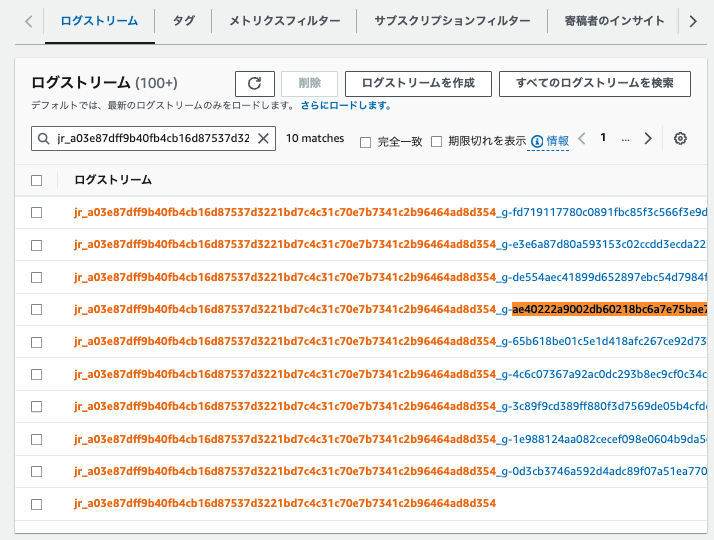
ログを検索すると、ログの内容から、g-から始まる番号はタスクIDを表していることがわかります。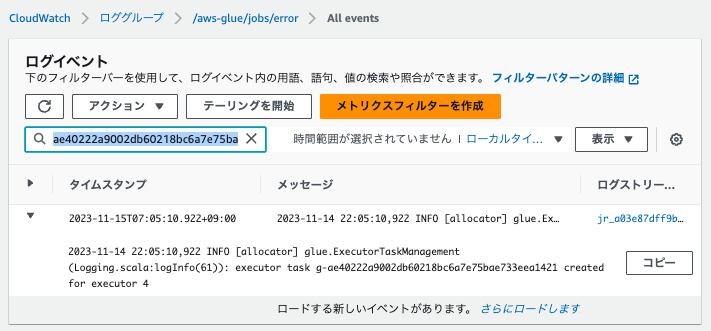
任意のログストリームでERRORを探すと見つからない場合もありました。
エラーの発生したタスクと、発生していないタスクがあるためだと思われます。
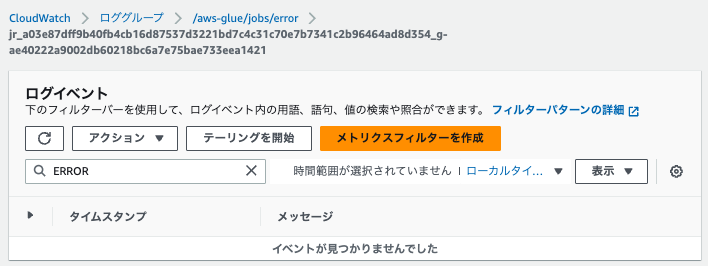
さきほど、「連続ログ記録の有効化によるドライバーログ」の章にて、エラーを確認したExecutor IDは、2、3および8でした。
タスクは特定のエグゼキュターに割り当てられているため、これらのIDのエグゼキュターに割り当てられているタスクのログから、エラーが確認できるはずです。
以下をそれぞれ実施することで、エラーが発生したタスクと、そのタスクに割り当てられたExecutor IDがわかります。
-
エラーログを含むログストリームを確認する
- 各ログストリーム内でタスクが割り当てられたエグゼキュターを特定する
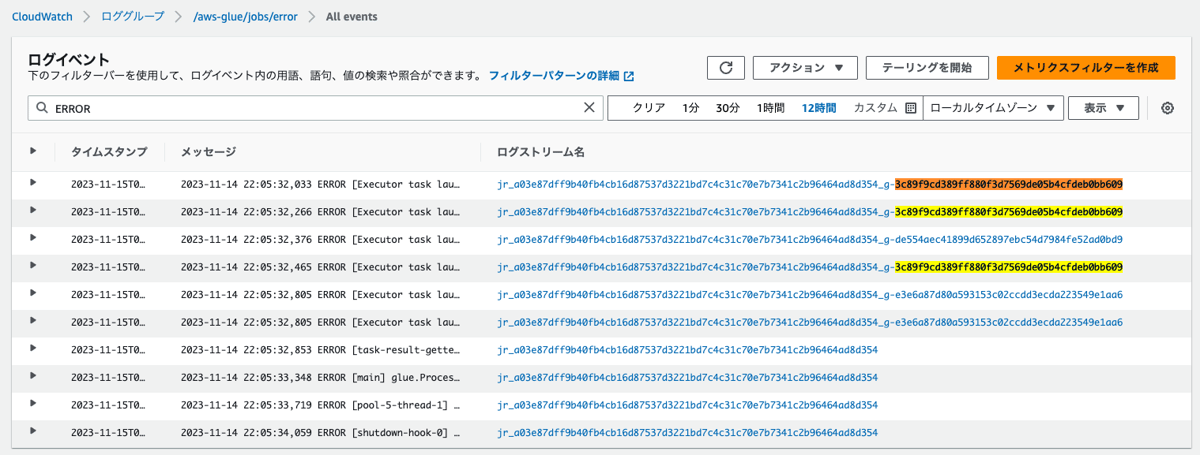
それぞれのタスクのログを確認します。
-
Executor IDが2のものに割り当てられたタスクのログ

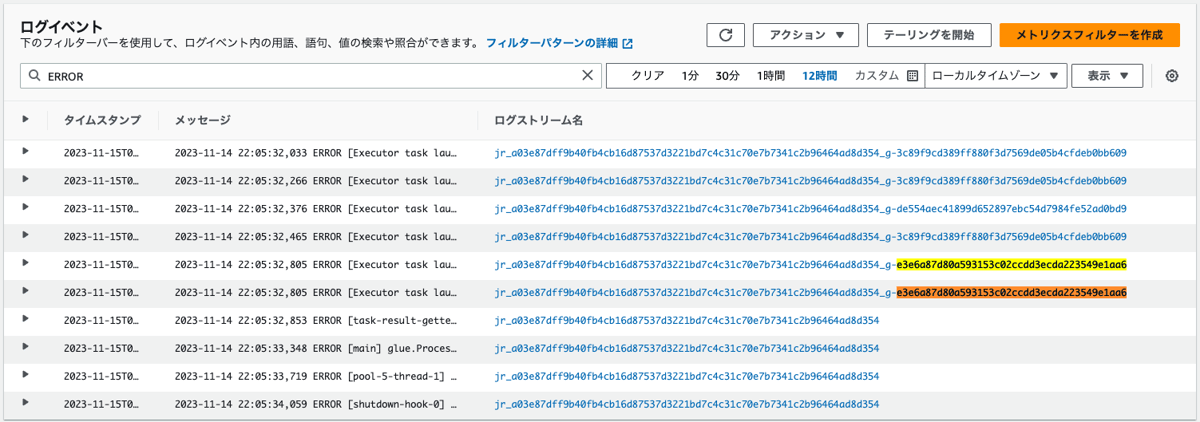
-
Executor IDが3のものに割り当てられたタスクのログ


-
Executor IDが8のものに割り当てられたタスクのログ
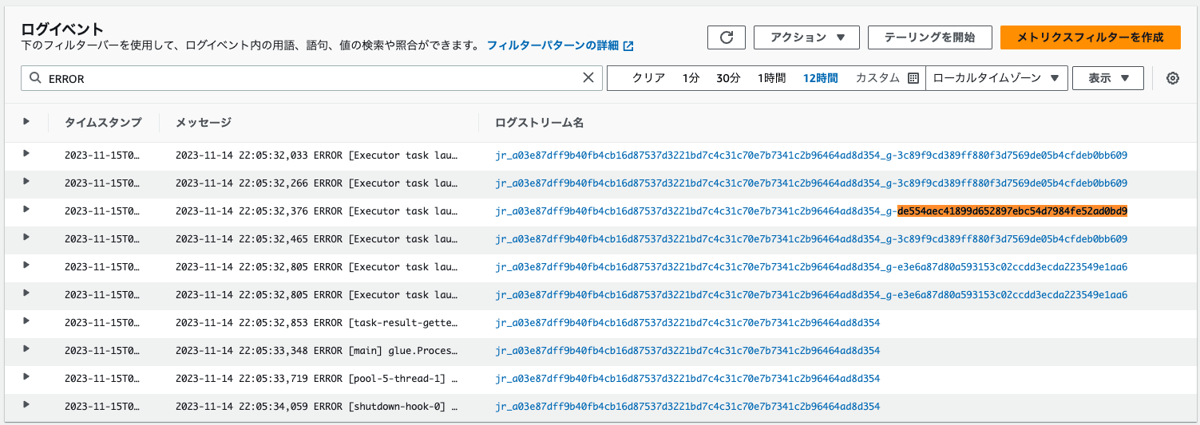

よって、タスクのエラーログからも、エラーが発生したExecutor IDは、2、3および8であることが確認できました。
以下でエラーが出力されているタスクの一例を示します(他の、エラーが出力されたタスクIDを含むログでも同様に、同じようなログが出力されていました)。
2023-11-14 22:05:32,465 ERROR [Executor task launch worker for task 8.2 in stage 0.0 (TID 37)] executor.Executor (Logging.scala:logError(98)): Exception in task 8.2 in stage 0.0 (TID 37)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/tmp/watanabe-sample.py", line 33, in <lambda>
File "/tmp/watanabe-sample.py", line 26, in data_multiplier_func
ModuleNotFoundError: No module named 'tensorflow'
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:559) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:86) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:68) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:512) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491) ~[scala-library-2.12.15.jar:?]
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460) ~[scala-library-2.12.15.jar:?]
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460) ~[scala-library-2.12.15.jar:?]
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) ~[?:?]
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:35) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.hasNext(Unknown Source) ~[?:?]
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:968) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:383) ~[spark-sql_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:890) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.scheduler.Task.run(Task.scala:138) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548) ~[spark-core_2.12-3.3.0-amzn-1.jar:?]
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1516) ~[spark-core_2.12-3.3.0-amzn-1.jar:3.3.0-amzn-1]
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551) ~[spark-core_2.12-3.3.0-amzn-1.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_382]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_382]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_382]
また、唯一タスクIDが含まれていないドライバーのログストリームで検索しても、いくつかのエラーを確認することができました。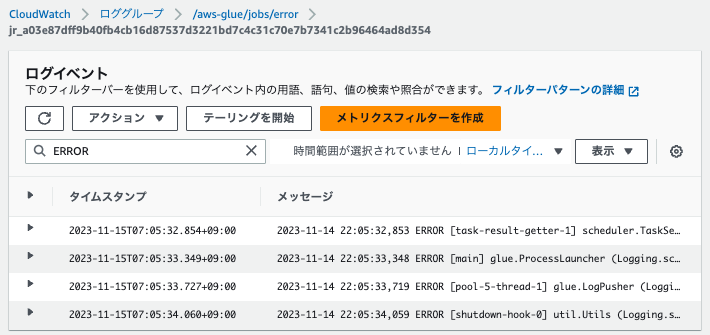
想定のエラーも見つかりましたので、本検証においてタスク単位およびドライバー単位のログストリームでエラーを確認できることがわかりました。
2023-11-14 22:05:33,348 ERROR [main] glue.ProcessLauncher (Logging.scala:logError(77)): Error from Python:Traceback (most recent call last):
File "/tmp/watanabe-sample.py", line 35, in <module>
print(factoredDf.collect())
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/dataframe.py", line 818, in collect
sock_info = self._jdf.collectToPython()
File "/opt/amazon/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1321, in __call__
return_value = get_return_value(
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 196, in deco
raise converted from None
pyspark.sql.utils.PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/tmp/watanabe-sample.py", line 33, in <lambda>
File "/tmp/watanabe-sample.py", line 26, in data_multiplier_func
ModuleNotFoundError: No module named 'tensorflow'
Glue interactive session のエラーログ
VisualETLでData previewを使用すると/aws-glue/sessions/errorにログが出力されます。
スクリプトの修正を試みると、以下の通り、ビジュアルモードからスクリプトモードになります。
Unlocking the job script will convert your job from visual mode to script-only mode. This action cannot be undone. To keep a copy of the visual-mode job, clone the job on the Jobs page of Glue Studio.
スクリプトモードだと、ビジュアルジョブエディタの機能である、Data previewが使用できなかったです。
よって、本章では、VisualETLで任意の処理を実行して、ログ出力しようと思います(エラーログの出力などは考慮しない)。
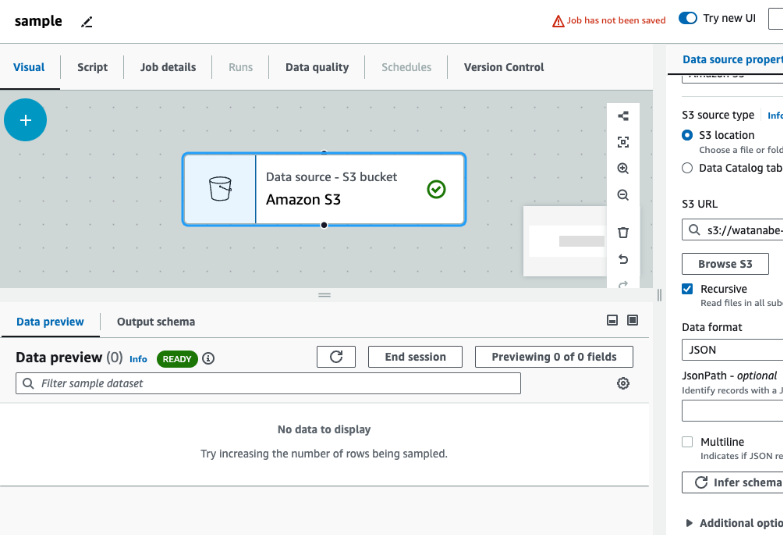
以下を設定してData previewを実行しました。
- Data preview用のIAMロールの設定
- 空のバケットを対象にData sourceを定義
- データフォーマットはJSONを指定
以上の設定を完了すると、実行がスタートします。
バケットは空なので、表示するデータがない旨のメッセージが出力されます。
/aws-glue/sessions/errorを確認します。
他のログのように、タスクがエグゼキュターに割り当てられています。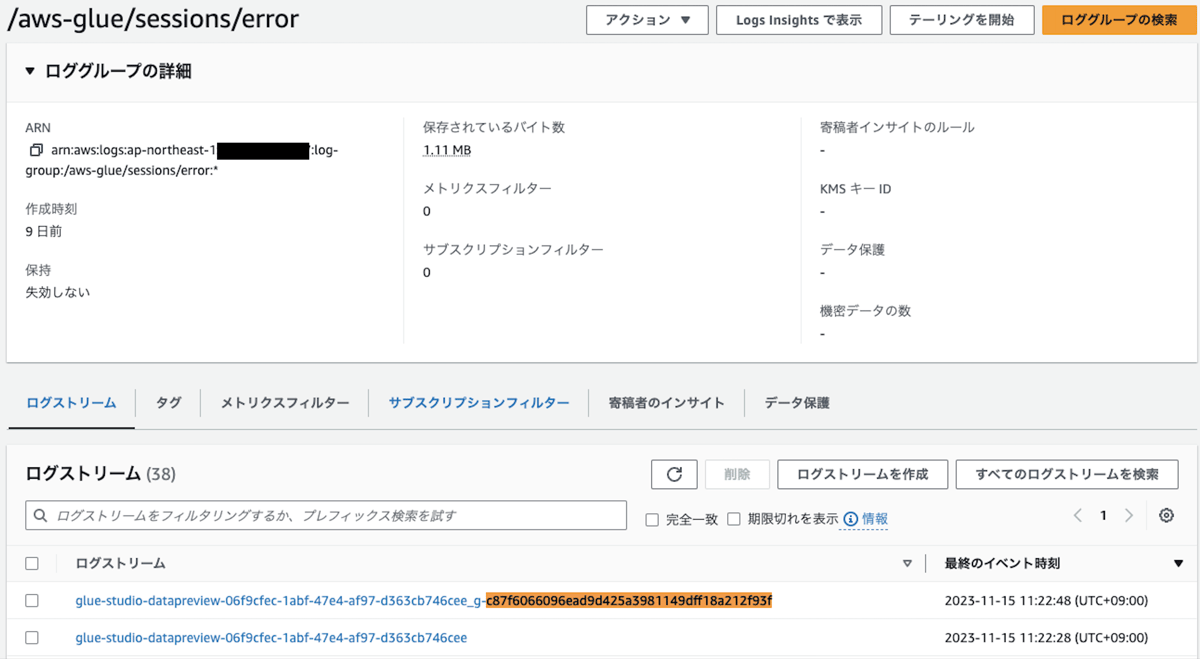
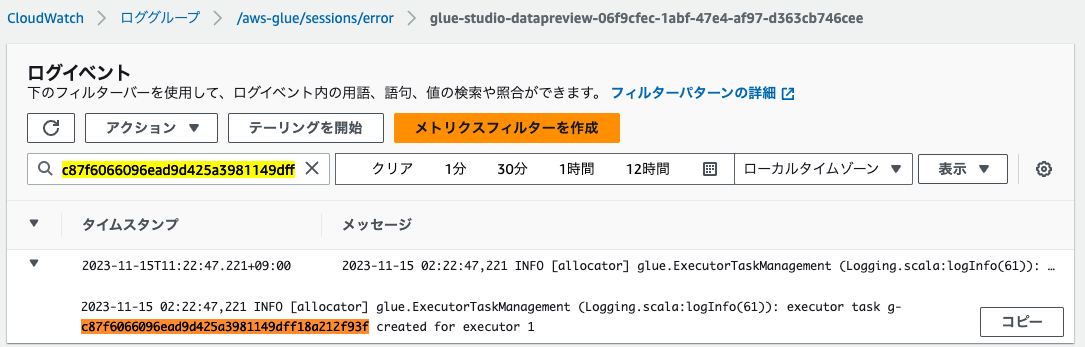
それぞれのログストリームを確認すると、他のログと同様、出力内容に差異がありました。
ストリームの命名から、エラーログ(/aws-glue/jobs/error)と同様に、タスク単位およびドライバー単位でログが出力されていると思われます。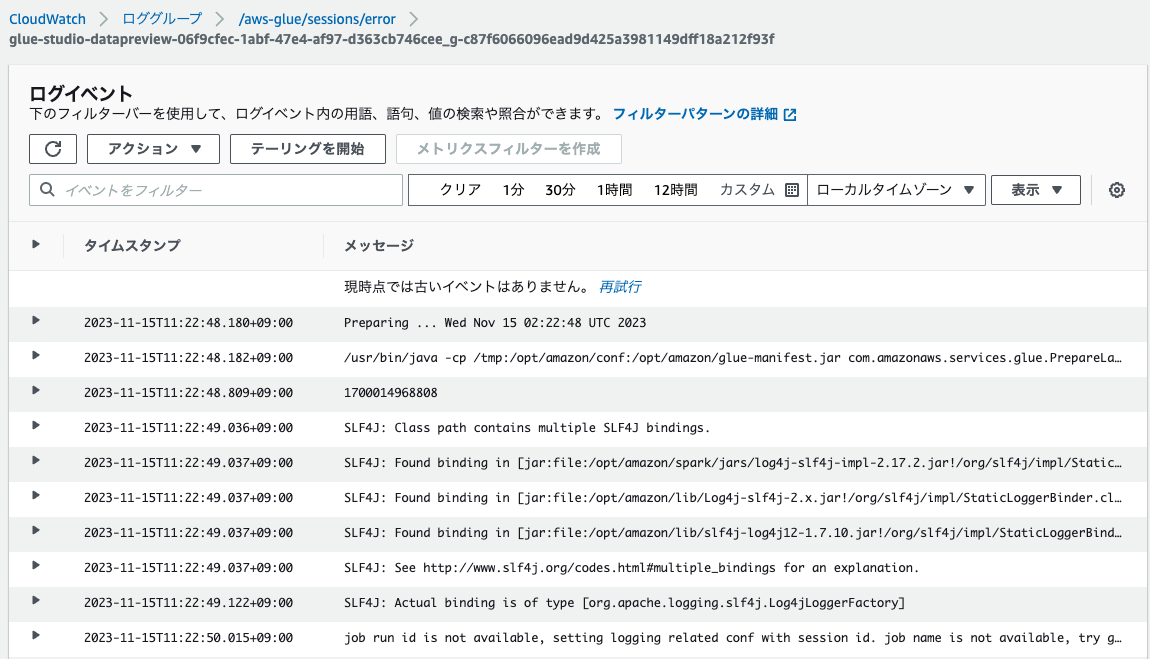
タスクIDが末尾についているログストリーム
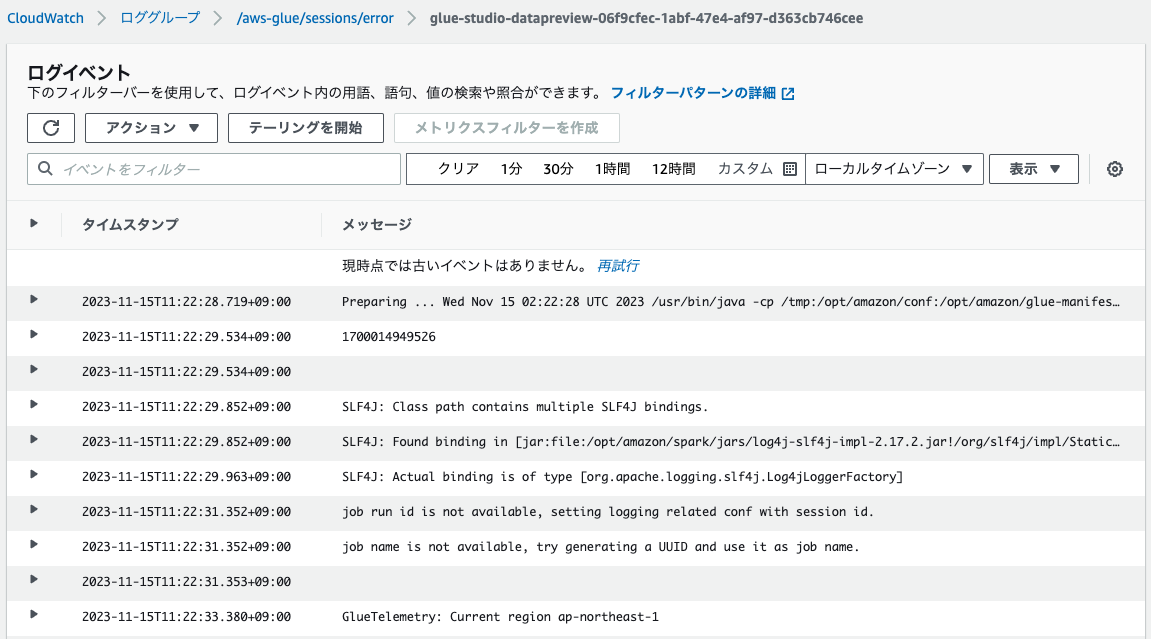
タスクIDが末尾にないログストリーム
まとめ
- AWS GlueジョブのCloudWatch Logsへ出力されるログは以下の通り
- /aws-glue/jobs/logs-v2
- 連続ログ記録の有効化によるドライバーログ
- エグゼキュター単位、ドライバー単位でログストリームが出力される
- /aws-glue/jobs/output
- Glue Spark ジョブ実行時における標準出力ログ
- /aws-glue/jobs/error
- Glue Spark ジョブ実行時におけるエラーログ
- タスク単位、ドライバー単位でログストリームが出力される
- エラー以外のログも出力される
- /aws-glue/sessions/error
- Glue Spark ジョブ実行時におけるエラーログ
- タスク単位、ドライバー単位でログストリームが出力される
- エラー以外のログも出力される
- /aws-glue/jobs/logs-v2
- 各タスクはエグゼキュターに割り当てられる







